![[S] Subversion](/images/svn-name-banner.svg)
如果您要为 Subversion 项目贡献代码,请先阅读此文档。
虽然 Subversion 最初由 CollabNet 赞助和托管 (https://www.collab.net/),但它是一个真正的开源项目,根据 Apache 许可证 2.0 版发布。Subversion 的许多开发者由他们的雇主付费来改进 Subversion,而许多其他人只是优秀的志愿者,他们有兴趣构建更好的版本控制系统。
社区主要通过 IRC、邮件列表和 Subversion 存储库存在。要参与
加入我们在 irc.libera.chat 的 #svn-dev 频道(使用 网页界面 或 Matrix 或任何 IRC 软件;存档 在此)。
加入 "dev"、"commits" 和 "announce" 邮件列表。dev 列表 (dev@subversion.apache.org) 是几乎所有讨论发生的地方。所有开发问题都应该发到那里,不过你可能想先查看一下列表存档。 "commits" 列表会收到自动提交邮件。有关详细信息,请参阅 https://subversion.org.cn/mailing-lists.html。
从 https://svn.apache.org/repos/asf/subversion/trunk/ 获取最新开发源代码的副本。
新的开发总是发生在 trunk 上。错误修复、增强功能和新功能从那里移植到各个发布分支。
几年来,Subversion 社区每年都会在柏林举行一次黑客马拉松:2016、2015、2014、2013、2012、2011 和 2010 [链接来自 archive.org,一些媒体链接无法使用]。
有很多方法可以加入项目,无论是编写代码,还是测试和/或帮助管理错误数据库。如果你想贡献,请查看
要提交代码,只需将你的补丁发送到 dev@subversion.apache.org。不,等等,先阅读完本文件,然后开始将补丁发送到 dev@subversion.apache.org。:-)
要帮助管理问题数据库,请查看问题摘要,查找和测试无效或重复其他问题的问题。这两种情况都很常见,前者是因为错误通常在代码中其他更改的副作用中被无意中修复,而后者是因为人们有时会提交问题,而没有注意到它已经被报告过。如果你不确定某个问题,请在 dev@subversion.apache.org 上发布问题。(“Subversion:我们在这里帮助你帮助我们!”)
另一种帮助方法是在某个平台上设置 Subversion 的自动化构建和测试套件运行,并将输出发送到 notifications@subversion.apache.org 邮件列表。有关更多详细信息,请参阅 邮件列表页面。
最后,尽管 Subversion 项目的本质是线上的,并且由此产生的用户联系抽象化,但重要的是要意识到,在所有贡献的背后都有真实的人。对待所有其他社区成员就像你希望被对待一样。审查贡献,而不是贡献者;不要惹恼他人,也不要轻易被惹恼。
设计
2000 年 6 月编写了一份 设计规范,现在已经过时了。但它仍然很好地介绍了存储库的内部工作原理以及 Subversion 的各个层。
API 文档
有关更多信息,请参阅关于 公共 API 文档 的部分。
增量编辑器
Karl Fogel 为 O'Reilly 2007 年出版的书籍 Beautiful Code: Leading Programmers Explain How They Think 撰写了一章,涵盖了 Subversion 增量编辑器接口 的设计和使用。
网络协议
WebDAV 使用 文档介绍了 Subversion 的 DAV 网络协议,它是一种扩展的 HTTP 方言,使用以“http://”或“https://”开头的 URL。
SVN 协议 文档包含对 Subversion ra_svn 网络协议的正式描述,它是在端口 3690(默认情况下)上的自定义协议,其 URL 以“svn://”或“svn+ssh://”开头。
用户手册
《版本控制与 Subversion》是一本由 O'Reilly 出版发行的书籍,详细介绍了如何有效地使用 Subversion。本书的文本是免费的,并且正在积极修订。在线版本可在 https://svnbook.subversion.org.cn/ 获取。XML 源代码和其他语言的翻译在 https://sourceforge.net/projects/svnbook/ 的自己的存储库中维护。
系统说明
系统特定方面的大量设计理念已在 notes/ 目录中的各个文件中记录。
在您贡献代码之前,您需要熟悉现有的代码库和接口。
检出一个 Subversion 的副本(如果您还没有提交访问权限的帐户,则可以匿名检出),这样您就可以查看代码。
在 'subversion/include/' 目录下有很多包含大量文档注释的头文件。如果你仔细阅读这些注释,你将对实现细节有一个很好的理解。以下是一个建议的阅读顺序。
基本构建块: svn_string.h, svn_error.h, svn_types.h
关键接口: svn_delta.h
客户端接口: svn_ra.h, svn_wc.h, svn_client.h
仓库和版本化文件系统: svn_repos.h, svn_fs.h
Subversion 试图通过仅使用 C89/C90 语法的 ANSI/ISO C 以及 Apache 可移植运行时 (APR) 库来保持可移植性。APR 是 Apache httpd 服务器使用的可移植性层,更多信息可以在 https://apr.apache.org/ 找到。
由于 Subversion 严重依赖 APR,因此在没有先浏览 APR 中的某些头文件(位于 'apr/include/' 目录下)的情况下,可能难以理解 Subversion。
内存池: apr_pools.h
文件系统访问: apr_file_io.h
哈希表和数组: apr_hash.h, apr_tables.h
Subversion 还试图提供可靠和安全的软件。这只有通过理解 C 编程语言中安全编程的开发人员才能实现。请参阅 'notes/assurance.txt' 以了解这背后的完整理由。具体来说,你应该认真阅读 David Wheeler 的《安全编程》(如 'notes/assurance.txt' 中所述)。如果你在任何时候对更改的安全影响有任何疑问,请在开发者邮件列表中寻求审查。
源代码树的粗略指南
doc/
用户和开发者文档。
tools/
与 Subversion 协同工作但 Subversion 不依赖的工具。tools/ 中的代码由 Subversion 项目共同维护,并与 Subversion 本身处于相同的开源版权下。
contrib/
与 Subversion 协同工作但 Subversion 不依赖的工具,由可能参与或不参与 Subversion 开发的个人维护。contrib/ 中的代码是开源的,但可能与 Subversion 本身具有不同的许可证或版权持有者。
subversion/
Subversion 本身的源代码(与外部库相对)。
subversion/include/
Subversion 库用户的公共头文件。
subversion/include/private/
Subversion 库内部共享的私有头文件。
subversion/libsvn_fs/
版本控制“文件系统”API。
subversion/libsvn_repos/
围绕 `libsvn_fs` 核心构建的存储库功能。
subversion/libsvn_delta/
树增量、文本增量和属性增量的通用代码。
subversion/libsvn_wc/
工作副本的通用代码。
subversion/libsvn_ra/
存储库访问的通用代码。
subversion/libsvn_client/
客户端操作的通用代码。
subversion/svn/
命令行客户端。
subversion/tests/
自动化测试套件。
Subversion 项目强烈建议在公共主干上进行活跃的开发。对主干的更改具有最高的可见性,并且可以从未发布的代码中获得最大的锻炼。为了使这有利于所有人,我们的主干始终保持稳定。它应该构建。它应该工作。它可能还没有准备好发布,但它肯定应该准备好进行测试。
我们还强烈建议将大型更改分解成几个较小的逻辑提交——每个提交都应满足上述稳定性要求。
也就是说,我们理解将所有这些策略应用于特别大的更改(新功能、全面代码重组等)几乎是不可能的。在这种情况下,您可能需要考虑使用专门用于您的开发任务的自定义分支。以下是一些使您的基于分支的开发工作顺利进行的指南。
基于分支的开发并没有特别复杂。您从主干(或从最适合作为您工作源和目标的任何分支)创建分支,并在该分支上进行工作。Subversion 的合并跟踪功能极大地帮助减少了以这种方式工作所需的思维负担,因此强烈建议您充分利用该功能(通过使用 Subversion 1.5 或更新的客户端,并对分支的根目录执行所有合并)。
有关您的分支日志消息的策略,请注意有关 编写日志消息 的部分。
如果您正在分阶段进行功能或错误修复,涉及多个提交,而一些中间阶段还不稳定到无法进入主干,那么请在 /branches 中创建一个临时分支。无需询问——直接创建即可。在临时分支中尝试实验性想法也是可以的。所有上述内容都适用于部分提交者和完整提交者。它甚至适用于其他 ASF 项目的提交者,但请与我们联系(在 dev@ 上)——介绍一下自己以及您计划处理的问题。
完成分支后——无论是将其合并到主干还是放弃——请记住将其删除。
另请参见 关于部分提交访问权限的部分,了解我们关于向实验性分支提供提交访问权限的政策。
对于您期望长期存在的分支,我们建议在分支根目录中创建一个名为 BRANCH-README 的文件,并定期更新它。此类文件为您提供了一个绝佳的中心位置来描述分支的以下方面
分支的基本目的:修复的错误或要实现的功能;相关的 issue 编号;围绕它的列表讨论线程;描述情况的设计文档。
您正在使用哪种分支管理风格:这是一个功能分支,它将定期与父分支保持同步,并最终重新集成回父分支?它是一个预计在可预见的未来不会合并回父分支的分支?它是否与任何其他分支相关?
您在分支上还需要完成哪些任务?这些任务是否有人认领?它们是否需要更多设计输入?其他人如何帮助您?
这是一个示例 BRANCH-README 文件,演示了我们正在讨论的内容
This branch exists for the resolution of issue #8810, per the ideas documented in /trunk/notes/frobnobbing-feature.txt. It is a feature branch, receiving regular sync merges from /trunk, and expected to be reintegrated back thereto. TODO: * compose regression tests [DONE] * add frob identification logic [STARTED (fitz)] * add nobbing bits []
为什么大惊小怪?因为这个项目理想化了沟通和协作,理解后者更有可能发生在将前者作为重点的时候。
只需记住,当您将分支合并回其源代码时,请删除 BRANCH-README 文件。
每个函数,无论是公共的还是内部的,都必须以一个文档注释开头,描述该函数的作用。文档应提及函数接收的每个参数、每个可能的返回值,以及(如果不明确)函数可能返回错误的条件。
对于内部文档,即使在实际声明中参数名称不是大写,也要在文档字符串中将参数名称写成大写,以便它们在人类读者眼中脱颖而出。
对于公共或半公共 API 函数,文档字符串应该放在 .h 文件中声明函数的上面;否则,它应该放在 .c 文件中函数定义的上面。
对于结构类型,请记录结构本身以及每个单独的成员。
对于实际的源代码,在内部记录每个函数的块,以便熟悉 Subversion 的人能够理解正在实现的算法。不要包含明显或过于冗长的文档;注释应该有助于理解代码,而不是阻碍它。
例如
/*** How not to document. Don't do this. ***/
/* Make a foo object. */
static foo_t *
make_foo_object(arg1, arg2, apr_pool_t *pool)
{
/* Create a subpool. */
apr_pool_t *subpool = svn_pool_create(pool);
/* Allocate a foo object from the main pool */
foo_t *foo = apr_palloc(pool, sizeof(*foo));
...
}
相反,记录相当大的代码块,像这样
/* Transmit the segment (if its within the scope of our concern). */
SVN_ERR(maybe_crop_and_send_segment(segment, start_rev, end_rev,
receiver, receiver_baton, subpool));
/* If we've set CURRENT_REV to SVN_INVALID_REVNUM, we're done
(and didn't ever reach END_REV). */
if (! SVN_IS_VALID_REVNUM(current_rev))
break;
/* If there's a gap in the history, we need to report as much
(if the gap is within the scope of our concern). */
if (segment->range_start - current_rev < 1)
{
svn_location_segment_t *gap_segment;
gap_segment = apr_pcalloc(subpool, sizeof(*gap_segment));
gap_segment->range_end = segment->range_start - 1;
gap_segment->range_start = current_rev + 1;
gap_segment->path = NULL;
SVN_ERR(maybe_crop_and_send_segment(gap_segment, start_rev, end_rev,
receiver, receiver_baton,
subpool));
}
阅读 Subversion 代码以了解文档在实践中的外观;特别是,请参阅 subversion/include/*.h 以获取 doxygen 示例。
我们使用 Doxygen 格式来编写公共接口文档。这意味着任何在公共头文件中出现的内容。生成的文档在 网站上发布,用于最新和一些较早的 Subversion 源代码。
我们只使用一小部分可用的 doxygen 命令 来标记我们的源代码。在编写 doxygen 文档时,以下约定适用
@a,在类型和宏名称前加上 @c。<tt>...</tt> 来显示多个单词,使用 @p 来显示打字机字体中的单个单词。TRUE、FALSE 和 NULL 应该全部大写。@defgroup 和 @{...@} 将它们分组在一起。有关命令的完整列表,请参阅 Doxygen 手册。
要获取最新的源代码,请运行
svn checkout https://svn.apache.org/repos/asf/subversion/trunk/ svn-trunk
并按照 INSTALL 文件中的说明操作。(如果您没有 svn 客户端,请 下载源代码包。)
如果您要实现的新功能或更改了大量代码,请务必先在 dev@ 列表中进行讨论。(IRC 上的 #svn-dev 也是在邮件列表讨论之前(而不是代替)进行快速反馈的合适场所。如果您在 IRC 上提问,请等待一段时间以获得回复,因为并非所有人都始终在线(尤其是在周末)。)这样社区就可以尽快表达对拟议功能或实现细节的担忧并提出改进建议——如果这些反馈越早提供(甚至在编写任何代码之前)而不是之后,对所有各方来说总是更好的。
如果您对补丁有任何疑问,请随时在 IRC 或 dev@ 上提问。
将补丁邮件发送到 dev@subversion.apache.org,邮件主题行以 [PATCH] 开头。这有助于我们的 补丁管理器 立即发现补丁。例如
Subject: [PATCH] fix for rev printing bug in svn status
如果补丁解决了特定问题,请也包含问题编号:“[PATCH] issue #1729: ...”。对该特定问题感兴趣的开发人员将知道阅读邮件。
一次补丁提交应该包含一个逻辑更改;请不要在一个提交中混合 N 个不相关的更改——而是发送 N 封单独的电子邮件。
使用 svn diff -x-p 从 Subversion 主干工作副本的顶部生成补丁。如果您要 diff 的文件不在版本控制下,您可以使用 diff -u 达到相同的效果。
请在您的补丁中包含一个日志消息。一个好的日志消息有助于潜在的审阅者理解您的补丁中的更改,并增加它被应用的可能性。您可以将日志消息放在电子邮件正文中,或放在补丁附件的顶部(见下文)。无论哪种方式,它都应该遵循 编写日志消息 中给出的指南,并用三个方括号括起来,如下所示
[[[
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
]]]
(方括号实际上不是日志消息的一部分,它们只是用来清楚地将日志消息与其周围的上下文区分开来。)
如果可能,请将补丁作为附件发送,其 MIME 类型为 text/x-diff、text/x-patch 或 text/plain。大多数人的邮件阅读器可以内联显示这些内容,并且将补丁作为附件可以让它们方便地从消息中提取补丁。永远不要以存档或压缩形式(例如,tar、gzip、zip、bzip2)发送补丁,因为这会阻止人们直接在他们的邮件阅读器中查看补丁。
如果您无法使用这些 MIME 类型之一附加补丁,或者补丁非常短,那么直接将其包含在消息正文中是可以的。但要注意:一些邮件编辑器会通过在长行的中间插入不需要的行中断来修改内联补丁。如果您认为您的邮件软件可能会这样做,那么请使用附件。
如果补丁实现了新功能,请确保在邮件中完整描述该功能;如果补丁修复了 bug,请详细描述 bug 并提供重现步骤。这些指南的例外情况是,当补丁解决问题数据库中的特定问题时,在这种情况下,只需在日志消息中引用问题编号,如 编写日志消息 中所述。
补丁在应用之前经过几轮反馈和更改是正常的。如果您的补丁没有立即被接受,不要灰心,这并不意味着您犯了错误,只是意味着有很多人查看每个代码提交,很少有补丁没有改进的空间。在讨论了人们对您补丁的反馈后,进行必要的更改并重新提交,等待下一轮反馈,然后重复此过程,直到某个提交者应用它。您可以在提交补丁之前查看并应用项目的 编码规范,从而避免一些迭代。
如果您一段时间没有收到回复,并且没有看到补丁被应用,这可能只是意味着人们真的很忙。继续重新发布,不要犹豫指出您仍在等待回复。可以这样想,补丁管理是高度可并行的,我们需要您承担管理和编码的份额。每个补丁都需要有人来引导它完成整个过程,而最适合这样做的人就是最初的提交者。
Subversion 项目中的提交者是指那些被授予直接提交更改到我们版本控制资源的权利的人。该项目是精英制的,这意味着(除其他事项外)项目治理由那些做工作的人来处理。提交访问权限有两种类型:完全访问权限和部分访问权限。完全访问权限意味着树中的任何地方,部分访问权限意味着仅限于该提交者特定的专业领域。虽然每个贡献都受到重视,无论其来源如何,但并非每个为 Subversion 贡献代码的人都会获得提交访问权限。
COMMITTERS 文件列出了所有提交者,包括完全提交者和部分提交者,并说明了每个部分提交者的域。
当某人成功贡献了几个非微不足道的补丁后,一些全权提交者,通常是审查和应用该贡献者最多补丁的人,会提议他们获得提交权限。此提议仅发送给其他全权提交者——随后的讨论是私密的,以便每个人都能坦率地发表意见。假设没有异议,则授予贡献者提交权限。该决定由共识做出;没有正式的规则来管理该程序,尽管通常如果有人强烈反对,则不会提供访问权限,或者以临时方式提供访问权限。
获得全权提交权限的主要标准是良好的判断力。
你不必是技术奇才,也不必展示对整个代码库的深入了解,才能成为全权提交者。你只需要知道自己不知道什么。如果你的补丁符合本文件中的指南,符合所有通常无法量化的编码规则(代码应可读、健壮、可维护等),并尊重“首先,不要伤害”的希波克拉底原则,那么你很可能会很快获得提交权限。你的补丁的大小、复杂性和数量并不像你在避免错误和最大程度地减少对其余代码的不必要影响方面所表现出的谨慎程度那样重要。许多全权提交者并没有做出主要的代码贡献,而是做了很多小的、干净的修复,每一个修复都是对代码的明确改进。(当然,这并不意味着项目需要一堆非常琐碎的补丁,其唯一目的是获得提交权限;知道什么值得发布补丁,什么不值得发布补丁,是展现良好判断力的一部分 :-))。
为了帮助开发人员发现新的提交者,我们在 特殊的记功格式 中记录补丁和其他贡献,然后解析该格式以生成一个浏览器友好的 贡献列表,该列表每晚更新。如果你想提议某人获得提交权限,并想查看他们的所有更改,那么 贡献列表 可能是最方便的地方。
一个全权提交者会赞助部分提交者。通常这意味着全权提交者已经应用了提议的部分提交者在同一区域的多个补丁,并且意识到如果该人直接提交,事情会更容易。赞助者在发出邀请之前,通常会建议私下@,但不是必需的;信任赞助者会使用良好的判断力。
赞助人会观察部分提交者前几次的提交,以确保一切顺利进行。
由部分提交者提交的补丁,即使不在该人的领域内,也可以由该提交者提交。这需要至少一名完整提交者的批准(通常表示为 +1 票)。在这种情况下,批准应在日志消息中注明,如下所示
Approved by: lundblad
任何完整提交者都可以随时为任何人提供对实验分支的提交访问权限。实验分支不一定有很高的合并到主干的可能性(尽管这始终是一个值得追求的目标)。同样重要的是,完整提交者——实际上所有完整提交者——将这些分支视为新开发人员的训练场,通过对提交提供反馈。这些分支的目标是将新代码引入 Subversion,并将新开发人员引入项目。另请参阅有关轻量级分支的部分,以及这封邮件
https://svn.haxx.se/dev/archive-2007-11/0848.shtml From: Karl Fogel <kfogel@red-bean.com> To: dev@subversion.tigris.org Subject: branch liberalization (was: Elego tree conflicts work) Date: Tue, 20 Nov 2007 10:49:38 -0800 Message-Id: <87y7cswy4d.fsf@red-bean.com>
当一个工具被接受到 contrib/ 区域时,我们会自动为其作者提供部分提交访问权限,以便在那里维护该工具。任何完整提交者都可以赞助此操作。通常不需要讨论或投票,但如果存在异议,则适用通常的决策程序(首先尝试达成共识,如果无法达成共识,则在完整提交者之间进行投票)。
contrib/ 下的代码必须是开源的,但不需要与 Subversion 本身具有相同的许可证或版权持有者。
任何提交者,无论是完整提交者还是部分提交者,都可以修复任何地方的明显拼写错误、语法错误和格式问题——在网页、API 文档、代码注释、提交消息等中。我们依靠提交者的判断来确定什么是“明显的”;如果您不确定,请询问。
无论何时调用“显而易见的修复”规则,请在您的提交的日志消息中说明。例如
------------------------------------------------------------------------ r32135 | stylesen | 2008-07-16 10:04:25 +0200 (Wed, 16 Jul 2008) | 8 lines Update "check-license.py" so that it can generate license text applicable to this year. Obvious fix. * tools/dev/check-license.py (NEW_LICENSE): s/2005/2008/ ------------------------------------------------------------------------
Subversion 是 ASF 的一部分,与 100 多个其他 ASF 项目 共享同一个代码库。虽然那些项目的提交者不被视为 Subversion 的完整或部分提交者,但他们可以提交 明显的修复 以及他们提交的补丁——前提是这些补丁已 获得完整提交者(或其领域内的部分提交者)的 +1。在这两种情况下,请遵循我们的 日志消息指南。
发布经理在 Subversion 项目中的作用是处理将代码稳定化、打包并发布给公众的过程。如果我们正在建造飞机,RM 将是检查施工清单、在机身喷涂航空公司标志并向客户交付成品的人。
因此,成为 RM 并没有真正的开发工作。你所需要做的所有工作都是非编码的:协调人员、集中信息,并作为公众声音宣布新的稳定版本。RM 需要执行许多重复性任务,这些任务要么没有自动化,因为还没有人编写工具,要么因为这些任务需要人工验证,这使得自动化变得有些多余。你可以在 制作 Subversion 版本 部分阅读有关发布过程的更多信息。
你可能在此时认为 RM 的职责并不光彩,你有点对了。如果你正在寻找一个能够带来名利地位的项目职位,你最好去实现 trunk 上真正需要完成的东西。如果你正在寻找一些真正帮助那些不关心版本的人专注于代码的东西,那么 RM 非常适合你。
为了鼓励更广泛地传播发布管理知识,RM 角色目前在不同的 受害者 志愿者之间轮换。
Subversion 通常有一个补丁经理,其工作是监视 dev@ 邮件列表,确保没有补丁“漏网”。
这意味着要监视所有包含“[PATCH]”邮件的线程,并根据线程的进展采取适当的行动。如果线程自行解决(因为补丁已提交,或者因为大家一致认为不需要应用补丁,或者其他原因),则无需采取进一步行动。但如果线程在没有明确决定的情况下消失,则需要将补丁保存在问题跟踪器中。这意味着将任何关于该补丁的讨论线程的摘要以及相关邮件列表存档的链接添加到跟踪器中的某个问题中。对于解决现有问题跟踪器项目的补丁,该补丁将保存到该项目中。否则,将创建一个正确类型的新问题——“DEFECT”、“FEATURE”或“ENHANCEMENT”(不是“PATCH”)——将补丁保存到该新问题中,并将“patch”关键字记录在该问题上。
补丁经理需要对 Subversion 有基本的技术理解,并能够快速浏览线程并大致了解是否达成一致,以及达成何种一致。它不需要实际的 Subversion 开发经验或提交权限。使用邮件阅读软件的专业知识是可选的,但建议 :-)。
当前的补丁管理器是:Gavin 'Beau' Baumanis <gavin@thespidernet.com>。
Subversion 的代码和头文件根据几个关键点进行隔离:库特定 vs. 库间;公共 vs. 私有。这种分离主要是由于我们对适当的模块化和代码组织的关注,但也因为我们作为广泛采用的公共 API 的提供者和维护者的承诺。当你在 Subversion 中编写新函数时,你需要仔细考虑这些问题,在进行过程中问自己一些问题
“我的新代码的使用者是否局限于单个库中的特定源代码文件?” 如果是这样,你可能想要在同一个源文件中使用一个静态函数。
“我的新函数是否属于该库中的其他源代码需要使用,但库*外部*不需要使用?” 如果是这样,你想要使用一个非静态的、双下划线命名的函数(例如 svn_foo__do_something),并在相应的库特定头文件中包含其原型。
“我的代码需要从不同的库访问吗?” 在这里,你需要回答一些额外的問題,例如“我的代码应该放在我原本要放置它的库中,还是应该放在更通用的实用程序库中,例如 libsvn_subr?” 无论哪种方式,你现在都在考虑使用库间头文件。但在你决定使用哪一个之前,请查看下一个问题...
“我的代码是否具有干净、可维护的 API,可以合理地永久维护,并为 Subversion 公共 API 提供价值?” 如果是这样,你将把原型添加到公共 API 中,直接放在 subversion/include/ 中。如果不是,请仔细检查你的计划——也许你没有选择最佳的方式来抽象你的功能。但有时,库需要共享一些对 Subversion 本身以外的其他软件来说毫无用处的函数。在这种情况下,请使用 subversion/include/private/ 中的私有头文件。
Subversion 使用 ANSI C,并遵循 GNU 编码标准,除了我们不在函数名和其参数列表的左括号之间添加空格。Emacs 用户可以加载 svn-dev.el 来获得正确的缩进行为(这里的大多数源文件会自动加载它,如果 `enable-local-eval` 设置得当)。
阅读 https://gnu.ac.cn/prep/standards.html 以获取 GNU 编码标准的完整描述。下面是一个简短的示例,展示了最重要的格式指南,包括我们不加空格的函数参数列表括号的例外情况。
char * /* func type on own line */
argblarg(char *arg1, int arg2) /* func name on own line */
{ /* first brace on own line */
if ((some_very_long_condition && arg2) /* indent 2 cols */
|| remaining_condition) /* new line before operator */
{ /* brace on own line, indent 2 */
arg1 = some_func(arg1, arg2); /* NO SPACE BEFORE PAREN */
} /* close brace on own line */
else
{
do /* format do-while like this */
{
arg1 = another_func(arg1);
}
while (*arg1);
}
}
一般来说,即使你确定运算符优先级,也要尽可能使用括号,并愿意添加空格和换行符来避免“代码压缩”。不要太担心垂直密度;使代码可读比在屏幕上多放一行更重要。
我们在代码和纯文本散文文件中使用分页符(Ctrl-L 字符,ASCII 12)作为节边界。每个节都以一个分页符开头,分页符之后紧跟着节标题。
这有助于使用 Emacs 分页命令的人,例如 `pages-directory` 和 `narrow-to-page`。这样的人并不像你想象的那么少,如果你想成为其中一员,那么在你的 .emacs 中添加 (require 'page-ext),然后输入 C-x C-p C-h。
对于错误消息,以下约定适用
只有在需要向 subversion/include/svn_error_codes.h 中找到的一般错误消息添加信息时,才提供特定的错误消息。
消息以大写字母开头。
尽量使消息少于 70 个字符。
不要在错误消息末尾添加句号(“.”)。
不要在错误消息中包含换行符。
引用信息使用单引号(例如 "'some info'")。
不要在错误消息中包含发生错误的函数名称。如果 Subversion 使用 '--enable-maintainer-mode' 配置标志编译,它会自行提供此信息。
在错误字符串中包含路径或文件名时,请确保对它们进行引用(例如 "Can't find '/path/to/repos/userfile'")。
在错误字符串中包含路径或文件名时,请确保在包含之前使用 svn_dirent_local_style() 将它们转换为 规范形式(因为传递到和从 Subversion API 的路径假定为规范形式)。
不要使用 Subversion 特定的缩写(例如,使用 "repository" 而不是 "repo",使用 "working copy" 而不是 "wc")。
如果你想在错误中添加解释,请报告它,然后用冒号和解释,如下所示
"Invalid " SVN_PROP_EXTERNALS " property on '%s': "
"target involves '.' or '..'".
可以在分号后添加建议或其他补充内容,例如
"Can't write to '%s': object of same name already exists; remove "
"before retrying".
请尽量遵守这些约定,避免使用“--”等其他分隔符来分隔错误消息的不同部分。
还可以阅读有关本地化的信息。
(假设您已经基本了解 APR 池的工作原理;有关详细信息,请参阅 apr_pools.h。)
使用 Subversion 库的应用程序必须在调用任何 Subversion 函数之前调用 apr_initialize()。
Subversion 的一般池使用策略可以概括为两个原则
创建池的调用级别是唯一可以清除或销毁该池的地方。
在无限次迭代时,在进入迭代之前创建一个子池,在循环中使用它,并在每次迭代开始时清除它,然后在循环完成后销毁它,如下所示
apr_pool_t *iterpool = svn_pool_create(scratch_pool);
for (i = 0; i < n; ++i)
{
svn_pool_clear(iterpool);
do_operation(..., iterpool);
}
svn_pool_destroy(iterpool);
为了支持上述规则,我们使用以下池名称作为约定来表示各种池生命周期
result_pool:应在其中分配函数输出的池。结果池声明应始终在函数参数列表中找到,而不要在局部块中找到。(但并非所有函数都需要或具有结果池。)
scratch_pool:应在其中分配所有函数局部数据的池。此池也由调用者提供,调用者可以选择在控制权返回到调用者时立即清除此池。
iterpool:迭代池,用于循环内部,如上例所示。
(注意:一些旧代码使用单个pool函数参数,该参数充当结果池和临时池。)
通过在循环边界数据中使用迭代池,您可以确保 O(1) 而不是 O(N) 内存泄漏,如果函数从循环内部突然返回(例如,由于错误)。这就是为什么你不应该为在整个函数中持续存在的数据创建子池,而应该使用调用者传入的池。当调用者的池被清除或销毁时,该内存将被回收。如果调用者在循环中调用被调用者,那么相信调用者会在每次迭代时清除池。相同的逻辑一直传播到调用堆栈的顶端。
您使用的池也有助于代码阅读者了解对象生命周期。给定对象仅在循环的一次迭代期间使用,还是需要在循环结束之后持续存在?例如,池选择表明这段代码中发生了很多事情
apr_hash_t *persistent_objects = apr_hash_make(result_pool);
apr_pool_t *iterpool = svn_pool_create(scratch_pool);
for (i = 0; i < n; ++i)
{
const char *intermediate_result;
const char *key, *val;
svn_pool_clear(iterpool);
SVN_ERR(do_something(&intermediate_result, ..., iterpool));
SVN_ERR(get_result(intermediate_result, &key, &val, ...,
result_pool));
apr_hash_set(persistent_objects, key, APR_HASH_KEY_STRING, val);
}
svn_pool_destroy(iterpool);
return persistent_objects;
除了某些在完全理解这些原则之前编写的遗留代码之外,Subversion 中几乎所有池的使用都遵循上述准则。
一种这样的遗留模式是在池中分配一个对象,将池存储在对象中,然后释放该池(直接或通过 close_foo() 函数)来销毁对象。
例如
/*** Example of how NOT to use pools. Don't be like this. ***/
static foo_t *
make_foo_object(arg1, arg2, apr_pool_t *pool)
{
apr_pool_t *subpool = svn_pool_create(pool);
foo_t *foo = apr_palloc(subpool, sizeof(*foo));
foo->field1 = arg1;
foo->field2 = arg2;
foo->pool = subpool;
}
[...]
[Now some function calls make_foo_object() and returns, passing
back a new foo object.]
[...]
[Now someone, at some random call level, decides that the foo's
lifetime is over, and calls svn_pool_destroy(foo->pool).]
这很诱人,但它违背了使用池的目的,即不必过多地担心单个分配,而是要关注整体性能和生命周期组。相反,foo_t 通常不应该有 `pool` 字段。只需在当前池中分配您需要的 foo 对象即可——当该池被清除或销毁时,它们将同时消失。
另请参阅 异常处理 部分,了解有关在池被销毁时如何清理与池关联的资源的详细信息。
总结
对象不应该拥有自己的池。对象被分配到由构造函数调用者定义的池中。调用者知道对象的生存期,并将通过池来管理它。
函数不应该为其操作创建/销毁池;它们应该使用调用者提供的池。同样,调用者更了解函数将如何使用、使用频率、使用次数等,因此它应该负责函数的内存使用。
例如,考虑一个在紧密循环中多次调用的函数。调用者在每次迭代时清除 scratch 池。因此,创建内部子池是不必要的,并且可能是巨大的开销;相反,函数应该只使用传入的池。
每当发生无界迭代时,都应该使用迭代子池。
鉴于以上所有内容,将池传递给每个函数几乎是强制性的。由于对象不会为自身记录池,并且调用者始终应该管理内存,因此每个函数都需要一个池,而不是依赖于某些隐藏的魔法池。在有限的情况下,对象可能会记录用于其构造的池,以便它们可以构造子部分,但这些情况应该仔细检查。
另请参阅 跟踪内存泄漏,了解有关诊断池使用问题的提示。
始终使用 APR_STATUS_IS_...() 宏来检查 APR 状态码(除了 APR_SUCCESS),而不是通过直接比较。这是为了便携到非 Unix 平台所需的。
好的,以下是如何在 Subversion 中使用异常。
异常存储在 svn_error_t 结构中
typedef struct svn_error_t
{
apr_status_t apr_err; /* APR error value, possibly SVN_ custom err */
const char *message; /* details from producer of error */
struct svn_error_t *child; /* ptr to the error we "wrap" */
apr_pool_t *pool; /* place to generate message strings from */
const char *file; /* Only used iff SVN_DEBUG */
long line; /* Only used iff SVN_DEBUG */
} svn_error_t;
如果您是错误的原始创建者,您会执行类似的操作
return svn_error_create(SVN_ERR_FOO, NULL,
"User not permitted to write file");
注意 NULL 字段... 表示此错误没有子错误,即它是最底层的错误。
另请参阅关于编写错误消息的部分。
Subversion 在内部使用 UTF-8 存储其数据。这也适用于“message”字符串。假设 APR 以当前区域设置返回其数据,因此任何由 APR 返回的文本都需要在包含在消息字符串中之前转换为 UTF-8。
如果您收到错误,您有三种选择
自己处理错误。使用您自己的代码,或者只调用原始的 svn_handle_error(err)。(此例程会展开错误堆栈并打印出消息,将它们从 UTF-8 转换为当前区域设置。)
当您的例程收到一个它打算忽略或自行处理的错误时,请务必使用 svn_error_clear() 清理它。任何未清除的此类错误都构成内存泄漏。
返回错误的函数不需要初始化其输出参数。
向上抛出错误,不作修改
error = some_routine(foo);
if (error)
return svn_error_trace(error);
实际上,更好的方法是使用 SVN_ERR() 宏,它执行相同操作
SVN_ERR(some_routine(foo));
向上抛出错误,将其包装在一个新的错误结构中,将其作为“child”参数包含在内
error = some_routine(foo);
if (error)
{
svn_error_t *wrapper = svn_error_create(SVN_ERR_FOO, error,
"Authorization failed");
return wrapper;
}
当然,有一个方便的例程可以创建一个包装错误,该错误具有与子错误相同的字段,除了您的自定义消息
error = some_routine(foo);
if (error)
{
return svn_error_quick_wrap(error,
"Authorization failed");
}
可以使用 SVN_ERR_W() 宏执行相同的操作(也应该这样做)
SVN_ERR_W(some_routine(foo), "Authorization failed");
在情况 (b) 和 (c) 中,重要的是要知道与池相关的例程分配的资源会在池销毁时自动清理。这意味着在传递错误之前不需要清理这些资源。因此,没有理由不使用 SVN_ERR() 和 SVN_ERR_W() 宏。与池相关的资源是
内存
文件
所有使用 apr_file_open 打开的文件在池清理时都会关闭。Subversion 在其 svn_io_file_* api 中使用此函数,这意味着使用 svn_io_file_* 或 apr_file_open 打开的文件将在池清理时关闭。
某些文件(例如锁文件)需要在操作完成后删除。APR 为此目的提供了 APR_DELONCLOSE 标志。以下函数创建在池清理时删除的文件
apr_file_open 和 svn_io_file_open(当传递 APR_DELONCLOSE 标志时)
svn_io_open_unique_file(当在 delete_on_close 中传递 TRUE 时)
如果使用 svn_io_file_lock 锁定文件,则会解锁这些文件。
当定义 SVN_ERR__TRACING 时,SVN_ERR() 宏将创建包装错误。这有助于开发人员确定导致错误的原因,并且可以通过 configure 的 --enable-maintainer-mode 选项启用。
有时,您只想返回被调用函数返回的内容,通常是在您自己的函数结束时。避免直接返回结果的诱惑
/* Don't do this! */
return some_routine(foo);
相反,使用 svn_error_trace 元函数返回该值。这确保在启用时堆栈跟踪正确发生。
return svn_error_trace(some_routine(foo));
就像几乎所有其他编程语言一样,C 具有不希望有的特性,这些特性使攻击者能够以可预测的方式使您的程序失败,通常对攻击者有利。这些指南的目的是让您了解 C 的缺陷,这些缺陷适用于 Subversion 项目。鼓励您在审查同行代码时牢记这些缺陷,因为即使是最熟练和偏执的程序员也会偶尔犯错。
输入验证是指定义合法输入并拒绝所有其他输入的行为。代码必须对所有不受信任的输入执行输入验证。
安全边界
Subversion 服务器代码中的安全边界必须被识别为这样,因为这使审计人员能够快速确定边界的质量。安全边界存在于运行代码可以访问用户无法访问的信息的地方,或者代码以高于发出请求的用户的权限运行的地方。此类代码的典型示例是执行访问控制的代码或设置了 SUID 位的应用程序。
对安全边界进行调用的函数必须包含对传递参数的验证检查。自身是安全边界的函数应审核接收到的输入,并在使用不正确的值调用时发出警报。
[### todo: 需要一些来自 Subversion 的示例...]
字符串操作
使用 apr_strings.h 中提供的字符串函数,而不是写入字符串的标准 C 库函数。APR 函数更安全,因为它们会自动进行边界检查和目标分配。虽然在理论上使用普通 C 字符串函数是安全的(例如,当您已经知道源和目标的长度时),但请始终使用 APR 函数,这样代码更不容易出错,更易于审查。
密码存储
帮助用户保护密码安全:当客户端本地读取或写入密码时,应确保文件模式为 0600。如果其他用户可以读取该文件,客户端应退出并显示一条消息,告知用户更改文件模式以防止暴露风险。
某些资源需要销毁才能确保应用程序正常运行。这些资源包括文件,尤其是在 Windows 上无法删除打开的文件。
在编写创建并返回流的 API 时,在后台,该流可能堆叠在文件或其他流上。为了确保正确销毁流所依赖的资源,必须正确调用其所依赖(拥有)的流的析构函数。
最初在 https://svn.haxx.se/dev/archive-2005-12/0487.shtml 中,后来在 https://svn.haxx.se/dev/archive-2005-12/0633.shtml 中,针对文件、流、编辑器和窗口处理程序,对这个问题进行了更一般的讨论。
正如 Greg Hudson 所说
经过考虑,我希望我们能做到以下几点
- 从底层对象读取或写入的流拥有该对象,即关闭流会关闭底层对象(如果适用)。
- 创建流的层(函数或数据类型)负责关闭它,除非上述规则适用。
- 窗口处理程序被认为是一种奇特的流,传递最终的 NULL 窗口被认为是关闭流。
如果你认为 apply_textdelta 是创建窗口处理程序,那么我认为我们并没有偏离太多。svn_stream_from_aprfile 并不拥有其子文件,svn_txdelta_apply 错误地承担了关闭传递给它的窗口流的责任,可能还存在其他偏差。
不过,上述规则有一个例外。当将流作为参数传递给函数时(例如:svn_client_cat2() 的“out”参数),该例程不能调用流的析构函数,因为它没有创建该资源。
如果 svn_client_cat2() 创建了一个流,它也必须调用该流的析构函数。根据上述模型,该流将调用“out”参数的析构函数。然而,这是错误的,因为销毁“out”参数的责任在于其他地方。
为了解决这个问题,至少在流的情况下,引入了 svn_stream_disown()。此函数包装了一个流,确保它不会被销毁,即使任何堆叠在其上的流可能会尝试这样做。
当您调用一个接受可变数量参数并期望列表以空指针常量(例如 apr_pstrcat)终止的函数时,不要使用 NULL 符号来终止列表。根据编译器和平台的不同,NULL 可能是一个指针大小的常量,也可能不是;如果不是,该函数可能会最终读取超出参数列表末尾的数据。
相反,请使用 SVN_VA_NULL(从 1.9 版开始在 svn_types.h 中定义),它保证是一个空指针常量。例如
return apr_pstrcat(cmd->temp_pool, "Cannot parse expression '",
arg2, "' in SVNPath: ", expr_err, SVN_VA_NULL);
除了 GNU 标准之外,Subversion 还使用以下约定
当使用路径或文件名作为大多数 Subversion API 的输入时,请确保使用 svn_dirent_internal_style() API 将它们转换为 Subversion 的内部/规范形式。或者,当从 Subversion API 接收路径或文件名作为输出时,请使用 svn_dirent_local_style() API 将它们转换为平台期望的形式。
仅使用空格缩进代码,不要使用制表符。制表符显示宽度没有标准化,而且手动调整使用空格的缩进更容易。
将行限制为 79 列,以便代码在最小的标准显示窗口中显示良好。(可能存在例外情况,例如,当声明一个 80 列文本块,其中有几列被缩进、引号等占用时,如果将每一行分成两行会很不合理地混乱。)
所有公开的函数、变量和结构体必须用相应的库名标识,例如 libsvn_wc 的 svn_wc_adm_open。所有在库私有头文件(例如 libsvn_wc/wc.h)中声明的库内部声明必须在库前缀后加上两个下划线(例如 svn_wc__ensure_directory)。所有仅对单个文件私有的声明(例如 libsvn_wc/update_editor.c 中的静态函数 get_entry_url)不需要任何额外的命名空间装饰。需要在库外部使用但仍非公开的符号放在 include/private/ 目录下的共享头文件中,并使用双下划线表示法。此类符号只能由 Subversion 核心代码使用。
回顾
/* Part of published API: subversion/include/svn_wc.h */
svn_wc_adm_open()
#define SVN_WC_ADM_DIR_NAME ...
typedef enum svn_wc_schedule_t ...
/* For use within one library only: subversion/libsvn_wc/wc.h */
svn_wc__ensure_directory()
#define SVN_WC__BASE_EXT ...
typedef struct svn_wc__compat_notify_baton_t ...
/* For use within one file: subversion/libsvn_wc/update_editor.c */
get_entry_url()
struct handler_baton {
/* For internal use in svn core code only:
subversion/include/private/svn_wc_private.h */
svn_wc__entry_versioned()
在 Subversion 1.5 之前,需要在库外部使用的私有符号被放在公共头文件中,并使用双下划线表示法。这种做法已被放弃,任何此类符号都是遗留的,为了 向后兼容性 而维护。
在可能被打印出来(或以其他方式提供给用户)的文本字符串中,只使用前导引号包围路径和其他可引用的内容。例如
$ svn revert foo
svn: warning: svn_wc_is_wc_root: 'foo' is not a versioned resource
$
以前有很多字符串使用反引号作为第一个引号(`foo' 而不是 'foo'),但这在某些字体中看起来很糟糕,而且还会弄乱一些人的自动高亮,因此我们最终决定始终使用前导引号。
如果您使用 Emacs,请在您的 .emacs 文件中添加类似以下内容,以便在需要时获得 svn-dev.el 和 svnbook.el
;;; Begin Subversion development section
(defun my-find-file-hook ()
(let ((svn-tree-path (expand-file-name "~/projects/subversion"))
(book-tree-path (expand-file-name "~/projects/svnbook")))
(cond
((string-match svn-tree-path buffer-file-name)
(load (concat svn-tree-path "/tools/dev/svn-dev")))
((string-match book-tree-path buffer-file-name)
;; Handle load exception for svnbook.el, because it tries to
;; load psgml, and not everyone has that available.
(condition-case nil
(load (concat book-tree-path "/src/tools/svnbook"))
(error
(message "(Ignored problem loading svnbook.el.)")))))))
(add-hook 'find-file-hooks 'my-find-file-hook)
;;; End Subversion development section
当然,您需要根据您的设置自定义路径。您还可以使正则表达式更具选择性地进行字符串匹配;例如,一位开发者说
> Here's the regexp I'm using:
>
> "src/svn/[^/]*/\\(subversion\\|tools\\|build\\)/"
>
> Two things to notice there: (1) I sometimes have several
> working copies checked out under ...src/svn, and I want the
> regexp to match all of them; (2) I want the hook to catch only
> in "our" directories within the working copy, so I match
> "subversion", "tools" and "build" explicitly; I don't want to
> use GNU style in the APR that's checked out into my repo. :-)
我们有一个传统,不使用个人作者的姓名标记文件(即,我们不会在源文件顶部特殊位置添加类似“作者:foo”或“@author foo”的代码行)。这样做是为了避免出现领地意识——即使一个文件只有一个作者,我们也希望确保其他人可以自由地进行修改。如果有人似乎对文件拥有个人所有权,其他人可能会不必要地犹豫。
在一个句子结束和下一个句子开始之间留两个空格。这有助于提高可读性,并允许人们使用其编辑器的句子移动和操作命令。
在整个代码中,还有许多其他不成文的约定,只有在有人无意中不遵守这些约定时才会注意到。只要尽力对做事的方式保持敏感,如有疑问,请咨询。
每次提交都需要一条日志消息。
日志消息的目标受众是已经熟悉 Subversion 的开发者,但不一定熟悉这次特定的提交。通常,当有人回过头来阅读更改时,他不再记得所有关于该更改的上下文。即使是他自己提交的更改也是如此!所有讨论、邮件列表线程和其他一切可能都被遗忘;关于更改内容的唯一线索来自日志消息和差异本身。人们也以惊人的频率重新审视更改:例如,可能是几个月后,原始提交已经完成,现在更改正在移植到维护分支。
日志消息是更改的介绍。
如果你正在分支上工作,请在你的日志消息前加上
On the 'name-of-branch' branch: (Start of your log message)
以一行指示更改的总体性质开始你的日志消息,并在必要时添加描述性段落。
这不仅有助于将开发者置于阅读日志消息其余部分的正确心态,而且还与“ASFBot”机器人配合良好,该机器人将每次提交的第一行回显到实时论坛(如 IRC)。(有关详细信息,请参阅 https://wilderness.apache.org/)
如果提交只是对一个文件进行一个简单的更改,那么你可以省略总体描述,直接进入详细描述,使用下面显示的标准文件名-符号格式。
在整个日志消息中,使用完整的句子,而不是句子片段。片段更容易产生歧义,而写出你的意思只需要几秒钟。某些片段,如“文档修复”、“新文件”或“新函数”是可以接受的,因为它们是标准的习语,所有其他细节都应该出现在源代码中。
日志消息应该列出所有受影响的函数、变量、宏、makefile 目标、语法规则等,包括本次提交中删除的符号的名称。这有助于人们以后在日志中搜索。不要将名称隐藏在通配符中,因为通配符部分可能是以后有人搜索的内容。例如,以下内容不好
* subversion/libsvn_ra_pigeons/twirl.c
(twirling_baton_*): Removed these obsolete structures.
(handle_parser_warning): Pass data directly to callees, instead
of storing in twirling_baton_*.
* subversion/libsvn_ra_pigeons/twirl.h: Fix indentation.
以后,当有人试图找出 `twirling_baton_fast` 发生了什么时,如果他们只搜索 “_fast”,可能找不到它。更好的条目应该是
* subversion/libsvn_ra_pigeons/twirl.c
(twirling_baton_fast, twirling_baton_slow): Removed these
obsolete structures.
(handle_parser_warning): Pass data directly to callees, instead
of storing in twirling_baton_*.
* subversion/libsvn_ra_pigeons/twirl.h: Fix indentation.
通配符在 `handle_parser_warning` 的描述中是可以的,但只是因为这两个结构在日志条目中的其他地方以全名提及。
你应该在日志消息中包含属性更改。例如,如果你要修改 trunk 上的“svn:ignore”属性,你可以在日志中添加类似以下内容
* trunk/ (svn:ignore): Ignore 'build'.
以上内容只适用于你维护的属性,不适用于 subversion 维护的属性,如“svn:mergeinfo”。
注意每个文件都有自己的条目,以“*”开头,文件内的更改按符号分组,符号用括号括起来,后面跟着冒号,然后是描述更改的文本。请遵守此格式,即使只更改了一个文件——一致性不仅有助于可读性,还允许软件自动对日志条目进行着色。
作为上述内容的例外,如果你在多个文件中进行了完全相同的更改,请在一个条目中列出所有更改的文件。例如
* subversion/libsvn_ra_pigeons/twirl.c,
subversion/libsvn_ra_pigeons/roost.c:
Include svn_private_config.h.
如果所有更改的文件都在源代码树的深处,你可以通过在更改条目之前记录公共前缀来缩短文件名条目
[in subversion/bindings/swig/birdsong]
* dialects/nightingale.c (get_base_pitch): Allow 3/4-tone
pitch variation to account for trait variability amongst
isolated populations Erithacus megarhynchos.
* dialects/gallus_domesticus.c: Remove. Unreliable due to
extremely low brain-to-body mass ratio.
如果你的更改与问题跟踪器中的特定问题相关,请在日志消息中包含类似“issue #N”的字符串,但请确保你仍然总结了更改的内容。例如,如果一个补丁解决了 issue #1729,那么日志消息可能是
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
尝试将相关的更改放在一起。例如,如果您创建了 `svn_ra_get_ansible2()`,并弃用了 `svn_ra_get_ansible()`,那么这两个更改应该在日志消息中彼此靠近。
* subversion/include/svn_ra.h
(svn_ra_get_ansible2): New prototype, obsoletes svn_ra_get_ansible.
(svn_ra_get_ansible): Deprecate.
对于大型更改或更改组,将日志条目分组到用空行分隔的段落中。每个段落应该是一组实现单个目标的更改,并且每个组应该以一两句话总结更改开始。当然,真正独立的更改应该在单独的提交中进行。
请参阅 署名,了解如何在提交他人的补丁或提交他们建议的更改时如何给予他人署名。
人们永远不需要通过日志条目来理解当前代码。如果您发现自己要在日志中写下重要的解释,您应该仔细考虑您的文本是否实际上属于注释,并与它解释的代码并排放置。以下是一个正确操作的示例
(consume_count): If `count' is unreasonable, return 0 and don't
advance input pointer.
然后,在 `cplus-dem.c` 中的 `consume_count` 中
while (isdigit((unsigned char)**type))
{
count *= 10;
count += **type - '0';
/* A sanity check. Otherwise a symbol like
`_Utf390_1__1_9223372036854775807__9223372036854775'
can cause this function to return a negative value.
In this case we just consume until the end of the string. */
if (count > strlen(*type))
{
*type = save;
return 0;
}
这就是为什么一个新函数,例如,只需要一个日志条目说“新函数”——所有细节都应该在源代码中。
您可以对命名所有更改内容的需求做出常识性的例外。例如,如果您进行了一项更改,该更改需要在程序的其余部分进行微不足道的更改(例如,重命名一个变量),您不必命名所有受影响的函数,您可以简单地说“所有调用者已更改”。重命名任何符号时,请记住提及旧名称和新名称,以便于追踪;请参阅 r861020 以获取示例。
总的来说,在通过搜索标识符来使条目易于查找,以及通过详尽无遗地浪费时间或产生不可读的条目之间存在着矛盾。请使用上述指南和您的最佳判断,并体谅您的同事开发人员。(此外,请使用“svn log”查看其他人是如何编写他们的日志条目的。)
文档或翻译的日志消息有一些比较宽松的指南。命名每个符号的要求显然不适用,如果更改只是在翻译等持续过程中的一次又一次的增量,甚至没有必要命名每个文件。只需简要总结更改,例如:“马达加斯加语翻译的更多工作”。请用英语编写您的日志消息,以便参与项目的所有人都能理解您所做的更改。
如果您正在使用分支来“检查点”您的代码,并且不认为它已准备好进行审查,请在日志消息的顶部,在“在 'xxx' 分支上的通知”之后,添加一些通知,例如
*** checkpoint commit -- please don't waste your time reviewing it ***
如果该分支上的后续提交需要审查,请在日志消息中提供相应的“svn diff”命令,因为 diff 可能涉及该分支上的两个非相邻提交,审查者不应该花时间弄清楚它们是哪些。
以一致且可解析的方式记录代码贡献非常重要。这使我们能够编写脚本以找出谁一直在积极贡献——以及他们贡献了什么——这样我们就可以 快速发现潜在的新提交者。Subversion 项目在日志消息中使用人类可读但机器可解析的字段来实现这一点。
提交他人编写的补丁时,在行首使用“Patch by: ”来指示作者
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Patch by: J. Random <jrandom@example.com>
如果多个个人编写了补丁,请将他们分别列在单独的行上——确保每个续行都以空格开头。非提交者应按姓名列出,如果已知,则列出电子邮件。完整和部分提交者应按其来自 COMMITTERS(该文件中最左侧的列)的规范用户名列出。此外,“me”是实际提交更改的人的公认简写。
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Patch by: J. Random <jrandom@example.com>
Enrico Caruso <codingtenor@codingtenor.com>
jcommitter
me
如果有人发现了错误或指出了问题,但没有编写补丁,请使用“Found by: ” (或“Reported by: ”) 来指示他们的贡献
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Found by: J. Random <jrandom@example.com>
如果有人提出了有用的建议,但没有编写补丁,请使用“Suggested by: ” 来指示他们的贡献
Extend the Contribulyzer syntax to distinguish finds from ideas. * www/hacking.html (crediting): Adjust accordingly. Suggested by: dlr
如果有人试用了一个补丁,请使用“Tested by: ”
Fix issue #23: random crashes on FreeBSD 3.14.
Tested by: Old Platformer
(I couldn't reproduce the problem, but Old hasn't seen any crashes since
he applied the patch.)
* subversion/libsvn_fs_sieve/obliterate.c
(cover_up): Account for sieve(2) returning 6.
如果有人审查了更改,请使用“Review by: ” (或“Reviewed by: ” 如果你更喜欢)
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Review by: Eagle Eyes <eeyes@example.com>
一个字段可以有多行,一个日志消息可以包含任何组合的字段
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Patch by: J. Random <jrandom@example.com>
Enrico Caruso <codingtenor@codingtenor.com>
me
Found by: J. Random <jrandom@example.com>
Review by: Eagle Eyes <eeyes@example.com>
jcommitter
有关贡献的更多详细信息应列在相应字段后面的括号内。这种旁注始终适用于上面的字段;在以下示例中,字段已为可读性而隔开,但请注意,间距是可选的,对于可解析性来说不是必需的
Fix issue #1729: Don't crash because of a missing file.
* subversion/libsvn_ra_ansible/get_editor.c
(frobnicate_file): Check that file exists before frobnicating.
Patch by: J. Random <jrandom@example.com>
(Tweaked by me.)
Review by: Eagle Eyes <eeyes@example.com>
jcommitter
(Eagle Eyes caught an off-by-one-error in the basename extraction.)
目前,这些字段
Patch by: Suggested by: Found by: Review by: Tested by:
是唯一正式支持的署名字段(其中“支持”意味着脚本知道要查找它们),并且它们在 Subversion 日志消息中被广泛使用。未来的字段可能采用“VERB by: ”的形式,有时有人可能会使用听起来很正式但实际上并非如此的字段——例如,有一些“Inspired by: ”的实例。这些是可以的,但尽量使用正式字段或括号内的旁注,而不是创建自己的字段。此外,当报告者已在问题中记录时,不要使用“Reported by: ”;相反,只需引用该问题即可。
查看 Subversion 的现有日志消息以了解如何在实践中使用这些字段。来自您的 trunk 工作副本顶部的此命令将有所帮助
svn log | contrib/client-side/search-svnlog.pl "(Patch|Review|Suggested) by: "
注意:在一些提交消息中看到的“Approved by: ”字段与这些署名字段完全无关,通常不会被脚本解析。它只是指示谁批准了部分提交者在其通常区域之外的提交,或者(在合并到发布分支的情况下)谁投票赞成将更改合并的标准语法。
Subversion 代码库镜像到 GitHub 上:https://github.com/apache/subversion/.
一些用户可能会在 GitHub 上创建 Pull Request。如果代码提交到 Subversion 代码库,请确保在日志消息中包含文本以自动关闭 Pull Request。
This fixes #NNN in GitHub
要管理 Pull Request 而不提交代码,您必须拥有与您的 ASF ID 关联的 GitHub 帐户,并且必须由 ASF Infra 为您的帐户分配 triager 角色。
Greg Stein 为 Subversion 编写了一个自定义构建系统,该系统之前一直使用 `automake` 和递归 Makefile。现在它使用单个顶级 Makefile,该文件从 Makefile.in(在版本控制下)生成。`Makefile.in` 反过来包含 `build-outputs.mk`,该文件由 `gen-make.py` 脚本从 `build.conf` 自动生成。因此,后两者在版本控制下,但 `build-outputs.mk` 则不在。
以下是 Greg 描述该系统的原始邮件,以及一些关于修改它的建议
From: Greg Stein <gstein@lyra.org>
Subject: new build system (was: Re: CVS update: MODIFIED: ac-helpers ...)
To: dev@subversion.tigris.org
Date: Thu, 24 May 2001 07:20:55 -0700
Message-ID: <20010524072055.F5402@lyra.org>
On Thu, May 24, 2001 at 01:40:17PM -0000, gstein@tigris.org wrote:
> User: gstein
> Date: 01/05/24 06:40:17
>
> Modified: ac-helpers .cvsignore svn-apache.m4
> Added: . Makefile.in
> Log:
> Switch over to the new non-recursive build system.
>...
Okay... this is it. We're now on the build system.
"It works on my machine."
I suspect there may be some tweaks to make on different OSs. I'd be
interested to hear if Ben can really build with normal BSD make. It
should be possible.
The code supports building, installation, checking, and
dependencies. It does *NOT* yet deal with the doc/ subdirectory. That
is next; I figured this could be rolled out and get the kinks worked
out while I do the doc/ stuff. Oh, it doesn't build Neon or APR yet
either. I also saw a problem where libsvn_fs wasn't getting built
before linking one of the test proggies (see below).
Basic operation: same as before.
$ ./autogen.sh
$ ./configure OPTIONS
$ make
$ make check
$ make install
There are some "make check" scripts that need to be fixed up. That'll
happen RSN. Some of them create their own log, rather than spewing to
stdout (where the top-level make will place the output into
[TOP]/tests.log).
The old Makefile.am files are still around, but I'll be tossing those
along with a bunch of tweaks to all the .cvsignore files. There are a
few other cleanups, too. But that can happen as a step two.
[ $ cvs rm -f `find . -name Makefile.rm`
See the mistake in that line? I didn't when I typed it. The find
returned nothing, so cvs rm -f proceeded to delete my entire
tree. And the -f made sure to delete all my source files, too. Good
fugging thing that I had my mods in some Emacs buffers, or I'd be
bitching.
I am *so* glad that Ben coded SVN to *not* delete locally modified
files *and* that we have an "undel" command. I had to go and tweak a
bazillion Entries files to undo the delete...
]
The top-level make has a number of shortcuts in it (well, actually in
build-outputs.mk):
$ make subversion/libsvn_fs/libsvn_fs.la
or
$ make libsvn_fs
The two are the same. So... when your test proggie fails to link
because libsvn_fs isn't around, just run "make libsvn_fs" to build it
immediately, then go back to the regular "make".
Note that the system still conditionally builds the FS stuff based
on whether DB (See 'Building on Unix' below) is available, and
mod_dav_svn if Apache is available.
Handy hint: if you don't like dependencies, then you can do:
$ ./autogen.sh -s
That will skip the dependency generation that goes into
build-outputs.mk. It makes the script run quite a bit faster (48 secs
vs 2 secs on my poor little Pentium 120).
Note that if you change build.conf, you can simply run:
$ ./gen-make.py build.conf
to regen build-outputs.mk. You don't have to go back through the whole
autogen.sh / configure process.
You should also note that autogen.sh and configure run much faster now
that we don't have the automake crap. Oh, and our makefiles never
re-run configure on you out of the blue (gawd, I hated when automake
did that to me).
Obviously, there are going to be some tweaky things going on. I also
think that the "shadow" builds or whatever they're called (different
source and build dirs) are totally broken. Something tweaky will have
to happen there. But, thankfully, we only have one Makefile to deal
with.
Note that I arrange things so that we have one generated file
(build-outputs.mk), and one autoconf-generated file (Makefile from
.in). I also tried to shove as much logic/rules into
Makefile.in. Keeping build-outputs.mk devoid of rules (thus, implying
gen-make.py devoid of rules in its output generation) manes that
tweaking rules in Makefile.in is much more approachable to people.
I think that is about it. Send problems to the dev@ list and/or feel
free to dig in and fix them yourself. My next steps are mostly
cleanup. After that, I'm going to toss out our use of libtool and rely
on APR's libtool setup (no need for us to replicate what APR already
did).
Cheers,
-g
--
Greg Stein, http://www.lyra.org/
以下是一些针对更改或测试配置/构建系统的建议
From: Karl Fogel <kfogel@collab.net>
To: dev@subversion.tigris.org
Subject: when changing build/config stuff, always do this first
Date: Wed 28 Nov 2001
Yo everyone: if you change part of the configuration/build system,
please make sure to clean out any old installed Subversion libs
*before* you try building with your changes. If you don't do this,
your changes may appear to work fine, when in fact they would fail if
run on a truly pristine system.
This script demonstrates what I mean by "clean out". This is
`/usr/local/cleanup.sh' on my system. It cleans out the Subversion
libs (and the installed httpd-2.0 libs, since I'm often reinstalling
that too):
#!/bin/sh
# Take care of libs
cd /usr/local/lib || exit 1
rm -f APRVARS
rm -f libapr*
rm -f libexpat*
rm -f libneon*
rm -f libsvn*
# Take care of headers
cd /usr/local/include || exit 1
rm -f apr*
rm -f svn*
rm -f neon/*
# Take care of headers
cd /usr/local/apache2/lib || exit 1
rm -f *
When someone reports a configuration bug and you're trying to
reproduce it, run this first. :-)
The voice of experience,
-Karl
构建系统是所有在 trunk 上工作的开发人员的重要工具。有时,对构建系统所做的更改对于一个开发人员来说运行良好,但无意中破坏了另一个开发人员的构建系统。
为了防止生产力下降,任何提交者(完全或部分)都可以立即恢复任何破坏其在所选平台上有效进行开发的能力的构建系统更改,作为常规操作,无需担心被指责反应过度。恢复更改的提交的日志消息应包含一个解释性说明,说明为什么恢复更改,其中包含足够的细节,以便在有人选择回复提交邮件时适合开始关于该问题的讨论。
但是,应注意不要进入“默认恢复模式”。如果您能快速解决问题,请这样做。如果没有,请停下来思考一分钟。在您思考之后,如果您仍然没有解决方案,请继续恢复更改,并将讨论带到列表中。
一旦更改被回滚,就由回滚更改的原始提交者决定是否重新提交其原始更改的修复版本,如果基于回滚提交者的理由,他们确信其新版本已修复,或者,在再次提交之前,将修改后的版本提交给回滚提交者进行测试。
有关如何使用和将测试添加到 Subversion 自动化测试框架的说明,请阅读 subversion/tests/README 和 subversion/tests/cmdline/README。
The ASF 基础设施 团队管理着一个 BuildBot 构建/测试农场。Subversion 项目的 BuildBot 水平线位于此处
有关构建服务的更多信息,请访问 ci2.apache.org。
如果您想接收有关 buildbot 构建和测试失败的通知,请订阅 notifications@ 邮件列表。
Buildbot 在 Infra 存储库 中配置,具体来说,是 subversion.py 文件。
From: Karl Fogel <kfogel@collab.net> Subject: writing test cases To: dev@subversion.tigris.org Date: Mon, 5 Mar 2001 15:58:46 -0600 Many of us implementing the filesystem interface have now gotten into the habit of writing the test cases (see fs-test.c) *before* writing the actual code. It's really helping us out a lot -- for one thing, it forces one to define the task precisely in advance, and also it speedily reveals the bugs in one's first try (and second, and third...). I'd like to recommend this practice to everyone. If you're implementing an interface, or adding an entirely new feature, or even just fixing a bug, a test for it is a good idea. And if you're going to write the test anyway, you might as well write it first. :-) Yoshiki Hayashi's been sending test cases with all his patches lately, which is what inspired me to write this mail to encourage everyone to do the same. Having those test cases makes patches easier to examine, because they show the patch's purpose very clearly. It's like having a second log message, one whose accuracy is verified at run-time. That said, I don't think we want a rigid policy about this, at least not yet. If you encounter a bug somewhere in the code, but you only have time to write a patch with no test case, that's okay -- having the patch is still useful; someone else can write the test case. As Subversion gets more complex, though, the automated test suite gets more crucial, so let's all get in the habit of using it early. -K
SVN_DBG 调试工具是一个 C 预处理器宏,它将调试输出发送到 stdout(默认)或 stderr,同时不干扰 SVN 测试套件。
它提供了一种替代调试器(如 gdb)的方案,或者提供额外的信息来帮助使用调试器。它可能在无法使用调试器的场景中特别有用。
svn_debug 模块包含两个调试辅助宏,它们将调用文件的行号和类似 printf 的参数打印到 #SVN_DBG_OUTPUT stdio 流(默认情况下为 #stdout)
SVN_DBG( ( const char *fmt, ...) ) /* double braces are neccessary */和
SVN_DBG_PROPS( ( apr_hash_t *props, const char *header_fmt, ...) )
控制 SVN_DBG 输出
--enable-maintainer-mode 时,SVN_DBG 会被启用。
SVN_DBG_QUIET 变量设置为 1。
SVN_DBG 和 SVN_DBG_PROPS 宏的实例。(即:不要忘记在病人身上留下手术刀!)
SVN_DBG 宏定义和代码位于
显示 SVN_DBG 宏使用示例的补丁
Index: subversion/libsvn_fs_fs/fs_fs.c
===================================================================
--- subversion/libsvn_fs_fs/fs_fs.c (revision 1476635)
+++ subversion/libsvn_fs_fs/fs_fs.c (working copy)
@@ -2303,6 +2303,9 @@ get_node_revision_body(node_revision_t **noderev_p
/* First, try a cache lookup. If that succeeds, we are done here. */
SVN_ERR(get_cached_node_revision_body(noderev_p, fs, id, &is_cached, pool));
+ SVN_DBG(("Getting %s from: %s\n",
+ svn_fs_fs__id_unparse(id),
+ is_cached ? "cache" : "disk"));
if (is_cached)
return SVN_NO_ERROR;
显示 SVN_DBG_PROPS 宏使用示例的补丁
Index: subversion/svn/proplist-cmd.c
===================================================================
--- subversion/svn/proplist-cmd.c (revision 1475745)
+++ subversion/svn/proplist-cmd.c (working copy)
@@ -221,6 +221,7 @@ svn_cl__proplist(apr_getopt_t *os,
URL, &(opt_state->start_revision),
&rev, ctx, scratch_pool));
+ /* this can be called with svn proplist --revprop -r <rev> */
+ SVN_DBG_PROPS((proplist,"The variable apr_hash_t *proplist contains: "));
if (opt_state->xml)
{
svn_stringbuf_t *sb = NULL;
'mod_dav_svn.so' 包含主要的 Subversion 服务器逻辑;它作为 mod_dav 中的一个模块运行,而 mod_dav 作为 httpd 中的一个模块运行。如果 httpd 可能使用动态共享模块,您可能需要在设置 mod_dav_svn 中的断点之前 set breakpoint pending on(在 ~/.gdbinit 中)。或者,您可以启动 httpd,中断它,设置断点,然后继续
% gdb httpd (gdb) run -X ^C (gdb) break some_func_in_mod_dav_svn (gdb) continue
-X 开关等效于 -DONE_PROCESS 和 -DNO_DETACH,它们分别确保 httpd 作为单个线程运行并保持连接到 tty。它一启动,就会坐等请求;这时您就可以按下 Ctrl+C 并设置断点。
您可能希望查看 Apache 的运行时日志
/usr/local/apache2/logs/error_log /usr/local/apache2/logs/access_log
以帮助确定可能出现的问题以及设置断点的位置。
或者,在工作副本中运行 ./subversion/tests/cmdline/davautocheck.sh --gdb 将使用该工作副本中的 mod_dav_svn 启动 httpd。然后,您可以针对它运行单个 Python 测试:./basic_tests.py --url=https://:3691/.
ra_svn 中的错误通常会以以下其中一条神秘的错误消息显现
svn: Malformed network data svn: Connection closed unexpectedly
(第一条消息也可能意味着数据流在隧道模式下被用户点文件或钩子脚本破坏;请参阅 问题 #1145。)第一条消息通常意味着您必须调试客户端;第二条消息通常意味着您必须调试服务器。
使用带有 --disable-shared --enable-maintainer-mode 的构建来调试 ra_svn 最容易。使用后一种选项,错误消息将准确地告诉您在何处设置断点;否则,请在 marshal.c:vparse_tuple() 的末尾查找返回“Malformed network data”错误的行号。
要调试客户端,只需在 gdb 中将其调出,设置断点,然后运行有问题的命令
% gdb svn
(gdb) break marshal.c:NNN
(gdb) run ARGS
Breakpoint 1, vparse_tuple (list=___, pool=___, fmt=___,
ap=___) at subversion/libsvn_ra_svn/marshal.c:NNN
NNN "Malformed network data");
有一些有用的信息
回溯将告诉你确切地是哪个协议交换失败了。
“print *conn” 将显示连接缓冲区。read_buf、read_ptr 和 read_end 代表读取缓冲区,它可以显示编组器正在查看的数据。(由于 read_buf 通常在 read_end 处没有以 0 结尾,因此要小心不要错误地假设缓冲区中有垃圾数据。)
格式字符串决定了编组器期望看到什么。
要调试守护进程模式下的服务器,请在 gdb 中将其拉起,设置断点(通常,客户端上的“连接意外关闭”错误表示服务器上的“格式错误的网络数据”错误,尽管它也可能表示核心转储),并使用“-X”选项运行它以服务单个连接
% gdb svnserve (gdb) break marshal.c:NNN (gdb) run -X
然后运行有问题的客户端命令。从那里,它就像调试客户端一样。
调试隧道模式下的服务器更麻烦。您需要在 svnserve 的 main() 顶部附近添加类似“{ int x = 1; while (x); }”的内容,并将生成的 svnserve 放入服务器上的用户路径。然后启动操作,在服务器上 gdb 附加进程,“set x = 0”,并根据需要逐步执行代码。
跟踪客户端和服务器之间的网络流量有助于调试。有几种方法可以进行网络跟踪(此列表并不详尽)。
在进行网络跟踪时,您可能需要禁用压缩 - 请参阅 servers 配置文件中的 http-compression 参数。
使用 Wireshark(以前称为“Ethereal”)来窃听对话。
首先,确保在同一个 wireshark 会话中捕获之间,您点击了“清除”,否则来自一个捕获(例如,HTTP 捕获)的过滤器可能会干扰其他捕获(例如,ra_svn 捕获)。
假设您已清除,那么
下拉“捕获”菜单,然后选择“捕获过滤器”。
如果调试 http://(WebDAV)协议,则在弹出的窗口中,选择“HTTP TCP 端口 (80)”(这将导致过滤器字符串“tcp port http”)。
如果调试 svn://(ra_svn)协议,则选择“新建”,为新过滤器命名(例如,“ra_svn”),并在过滤器字符串框中键入“tcp port 3690”。
完成后,单击“确定”。
再次转到“捕获”菜单,这次选择“接口”,然后单击相应接口旁边的“选项”(您可能想要接口“lo”,即“环回”,假设服务器将在与客户端相同的机器上运行)。
通过取消选中相应的复选框来关闭混杂模式。
单击右下角的“开始”按钮开始捕获。
运行您的 Subversion 客户端。
操作完成后,点击停止图标(以太网接口卡上的红色 X),或者点击捕获->停止。现在您已获得捕获数据,它看起来像一个巨大的行列表。
点击协议列进行排序。
然后,点击第一条相关行进行选择;通常这只是第一行。
右键点击,选择跟踪 TCP 流。您将看到 Subversion 客户端 HTTP 转换的请求/响应对。
以上说明适用于 Wireshark 的图形版本(版本 0.99.6),不适用于命令行版本,即“tshark”(对应于“tethereal”,在 Wireshark 称为 Ethereal 的时候)。
另一种方法是在 Subversion 客户端和服务器之间设置一个日志代理。一个简单的方法是使用 socat 程序。例如,要记录与 svnserve 实例的通信,运行以下命令
socat -v TCP-LISTEN:9630,reuseaddr,fork TCP4:localhost:svn
然后使用 svn://127.0.0.1:9630/ 的 URL 基地址运行您的 svn 命令;socat 将从端口 9630 转发流量到正常的 svnserve 端口(3690),并将双向的所有流量打印到标准错误,并在其前面加上 < 和 > 符号以显示流量方向。
要记录来自加密 https:// 连接的可读 HTTP,运行一个使用 TLS 连接到服务器的 socat 代理
socat -v TCP-LISTEN:9630,reuseaddr,fork OPENSSL:example.com:443
然后将其用作普通 http:// 连接的代理
svn ls http://example.com/svn/repos/trunk \
--config-option servers:global:http-proxy-host=localhost \
--config-option servers:global:http-proxy-port=9630 \
--config-option servers:global:http-compression=no
socat 代理记录纯 HTTP,而所有与服务器的网络流量都使用 TLS 加密。
如果您正在调试 http 客户端/服务器设置,可以使用网络调试代理,例如 Charles 或 Fiddler.
设置好代理后,您需要配置 Subversion 使用该代理。这可以通过 servers 配置文件中的 http-proxy-host 和 http-proxy-port 参数来完成。您也可以使用这些选项在命令行中指定代理:--config-option 'servers:global:http-proxy-host=127.0.0.1' --config-option 'servers:global:http-proxy-port=8888'.
我们使用 APR 池,这使得我们在严格意义上很少出现内存泄漏;我们分配的所有内存最终都会被清理。但有时操作会占用比预期更多的内存;例如,检出大型源代码树不应该比检出小型源代码树占用更多内存。当这种情况发生时,通常意味着我们正在从生命周期过长的池中分配内存。
如果您有喜欢的内存泄漏跟踪工具,您可以使用 --enable-pool-debug 配置(这将使每个池分配使用它自己的 malloc()),安排在操作中间退出,然后转到它。如果没有,这里还有另一种方法
使用 --enable-pool-debug=verbose-alloc 配置。确保重新构建所有 APR 和 Subversion,以便每个分配都获得文件和行信息。
运行操作,将 stderr 管道到文件。希望您有充足的磁盘空间。
在文件中,您将看到许多类似于以下内容的行
POOL DEBUG: [5383/1024] PCALLOC ( 2763/ 2763/ 5419) \
0x08102D48 "subversion/svn/main.c:612" \
<subversion/libsvn_subr/auth.c:122> (118/118/0)
您最关心的是第十个字段(带引号的字段),它为您提供了创建此分配的池的文件和行号。转到该文件和行,并确定池的生存期。在上面的示例中,main.c:612 表示此分配是在 svn 客户端的顶级池中进行的。如果这是一个在操作过程中多次重复的分配,则表明存在内存泄漏的来源。第十一个字段(带括号的字段)提供了分配本身的文件和行号。
Subversion 项目欢迎对网站进行改进。但是,这个过程并不像在浏览器中点击“另存为”、编辑和发送更改那样简单。一方面,许多页面实际上是由三个或更多个文件组成的,因此浏览器不会保存正确渲染的副本。
因此,如果您计划提交重大更改,我们建议您获取源代码副本并设置测试镜像以检查您的更改。
当然,对于小的更改,只需目视检查补丁通常就足够了。
网站的源代码可从 Subversion 存储库获取。要浏览源代码,请访问 https://svn.apache.org/repos/asf/subversion/site/
要将副本下载到 ~/projects/svn(本页其余部分使用的位置),请使用以下命令
mkdir -p ~/projects/svn cd ~/projects/svn svn co https://svn.apache.org/repos/asf/subversion/site/ site
如果您下载到其他位置,则需要调整 Web 服务器配置中的路径以指向该位置。
Subversion 网站使用服务器端包含 (SSI) 在 Web 服务器内组装页面。这意味着要验证您可能希望进行的任何更改,您需要通过连接到安装在您系统上的服务器的 Web 浏览器查看相关页面,无论是 Apache 2.2 还是 Apache 2.4。
以下步骤应提供一个Apache 虚拟主机,该虚拟主机在 Unix 类型系统上正确呈现 Subversion 网站的本地副本。这很可能位于/etc/apache2, /etc/httpd 或类似目录下,具体取决于您的系统。这些说明已在 Apache 2.2 和 Apache 2.4 上测试。
/home/user/projects/svn/site中。site/publish目录作为主服务器或虚拟主机的 DocumentRoot。mod_include.so。Options +Includes
AddOutputFilter INCLUDES .html
将所有内容整合在一起,一个示例虚拟主机配置如下
<VirtualHost *:8080>
ServerAdmin webmaster@localhost
DocumentRoot /home/user/projects/svn/site/publish
<Directory /home/user/projects/svn/site/publish/>
Options +Includes
AddOutputFilter INCLUDES .html
</Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
# Possible values include: debug, info, notice, warn, error, crit,
# alert, emerg.
LogLevel debug
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
重新启动或重新加载服务器后,如果您使用以下链接,您应该会看到Subversion 社区指南 Web 更改页面的副本:
http://127.0.0.1:8080/docs/community-guide/(none)#web_mirror
请验证对网站进行重大更改的所有补丁。
如果您已按照本页面的建议设置了网站镜像,请使用命令行获取已更改页面的正确呈现副本,方法是
wget http://127.0.0.1:8080/docs/community-guide/YOUR_CHANGED_PAGE.html
然后将生成的 文件上传到 HTML 验证器,例如,W3C 验证器服务。
在为有关项目网页的补丁编写日志消息时,例如
https://subversion.org.cn/docs/community-guide/some_page.html#section-name
在日志消息中列出补丁中修改的文件的名称,相对于site/目录,并列出添加或修改的节的锚点,如下所示
* docs/community-guide/some_page.html (section-name): fixed issue xyz
有关 Subversion 修补程序要求的完整讨论,请遵循项目通用修补程序指南和日志消息指南。
以下建议基于多年 Subversion 邮件列表的经验,并针对这些列表中最常遇到的问题。它不应被视为邮件列表礼仪的完整指南——如果你需要,可以在网上轻松找到其中之一。
如果你在发帖到我们的邮件列表时遵循这些约定,你的帖子更有可能被阅读和回复。
如有疑问,请邮件users@subversion.apache.org,而不是 dev@subversion.apache.org。users@ 列表上有许多经验丰富的人(包括一些 Subversion 的维护者)——他们可能能够回答你的问题,或者如果你认为你发现了一个错误,他们可以确定它是否是一个真正的错误。即使你想建议一个新功能,你也应该发帖到 users@:许多功能建议都是之前讨论过的想法,users@subversion.apache.org 邮件列表上的某个人通常能够告诉你你的建议是否属于这种情况。
请不要在 users@ 上无法获得答案后,将帖子作为最后手段发到 dev@。这两个列表有不同的章程:users@ 是一个支持论坛,dev@ 是一个开发讨论列表。当一个支持问题在 users@ 上没有得到答复时,这是不幸的,但这并不意味着这个问题适合 dev@。
当然,如果邮件是关于 Subversion 中的潜在错误,并且在 users@ 上没有得到任何反应,那么在 dev@ 上询问是可以的——错误是一个开发主题。而且补丁应该始终直接发送到 dev@。
有时,当对某个主题充满热情时,人们会忍不住回复邮件线程中的每条消息。请不要这样做。我们的邮件列表已经流量很大,回复每条消息只会增加噪音。
相反,请阅读整个邮件线程,仔细思考你想要说的话,选择一条消息进行回复,然后陈述你的想法。偶尔可能需要回复线程中的两条单独的消息,但只有当主题开始分歧时才这样做。
请勿使用超过 72 列的文本行。许多人使用 80 列终端阅读电子邮件。将文本写成 72 列,可以为将来回复中添加的引号字符留出空间,而不会强制重新换行。当然,72 列的限制仅适用于邮件正文部分。如果您要发布补丁,请参阅关于补丁的部分。
一些邮件程序会进行一种自动换行,即在您撰写邮件时,显示屏会显示实际上不存在的换行符。当邮件到达列表时,它将不会具有您认为的换行符。如果您的邮件编辑器执行此操作,请查找可以调整的设置以使其显示真实的换行符。
每个句子的第一个字母大写,并使用段落。如果您要显示屏幕输出或其他类型的示例,请将其偏移,使其与正文明显分开。如果您不这样做,您的邮件的可读性将大大降低,许多人根本不会费心阅读它。
回复列表帖子时,请确保使用邮件阅读器的“跟进”或“回复所有人”或“群组回复”功能。否则,您的邮件只会发送给原始帖子的作者,而不是整个列表。除非有私下回复的理由,否则始终最好回复列表,以便每个人都可以观看和学习。(此外,许多经常收到对其帖子的私人回复的人表示,他们更希望这些回复发送到列表中。)
请注意,Subversion 邮件列表不会修改 Reply-to 标头以将回复重定向到列表。它们会保留 Reply-to 设置为原始发件人设置的值,原因列在 https://www.unicom.com/pw/reply-to-harmful.html 中,特别是“最小损害原则”和“找不到回家的路”部分。有时,有人会发帖询问为什么我们不设置 Reply-to 标头。有时,那个人会提到 https://marc.merlins.org/netrants/reply-to-useful.html,其中给出了修改 Reply-to 字段的理由。列表管理员了解这两份文档,并认为双方的论点都有道理,但最终选择不修改 Reply-to 标头。请不要再提起这个话题。
不要通过回复现有帖子来开始一个新的主题(主题)。相反,请开始一个新的邮件,即使这意味着您必须手动写出列表地址。如果您回复现有帖子,您的邮件阅读器可能会包含元数据,将您的帖子标记为该主题的后续内容。更改 Subject 标头不足以防止这种情况!许多邮件阅读器仍然会保留足够的元数据,将您的帖子放到错误的主题中。如果发生这种情况,不仅有些人不会看到您的帖子(因为他们忽略了该主题),而且阅读该主题的人也会浪费时间阅读您的主题外帖子。避免这种情况最安全的方法是永远不要使用“回复”来开始一个新主题。
(问题的根源实际上是某些邮件界面没有表明“回复”功能生成的邮件与新邮件不同。如果您使用的是此类程序,请考虑向其开发人员提交增强请求或补丁,使其显示区别。)
如果您需要在保留主题的同时更改 Subject 标头(可能是因为主题已经转向了其他主题),请在新的主题下发布帖子,并在括号中包含旧的主题,例如
Blue asparagus
|
|_ Re: Blue asparagus
|
|_ Yellow elephants (was: Re: Blue asparagus) <-- ### switch ###
|
|_ Re: Yellow elephants
请不要反射性地指责人们顶帖。“顶帖”是指将回复文本放在引用文本之上,而不是与之交错或放在其下方。通常,引用文本为理解回复提供了必要的上下文,因此顶帖是一种阻碍。有时,人们在应该交叉发布或底部发布时会顶帖,而其他人则为此指责他们。如果您必须指责,请委婉地指责,当然不要为了指出这样的小问题而专门发帖。甚至在某些情况下,顶帖更可取——例如,当回复很短且通用,并且适用于引用文本的整个长段落时。因此,顶帖始终是一个判断问题,无论如何,即使在不恰当的情况下,它也不是什么大问题。
如果您来这里是为了寻求关于如何引用的建议,而不是关于如何不因人们的糟糕引用习惯而指责他们的建议,请参见 https://www.netmeister.org/news/learn2quote.html(德语:http://www.afaik.de/usenet/faq/zitieren/download/zitieren-alles.html)。
有关如何提交补丁的建议,请参见 此处。请注意,您可以提交补丁来修改这些网页,也可以修改代码;网页的仓库 URL 为 https://svn.apache.org/repos/asf/subversion/site/。
如果可能,请使用 ASCII 或 ISO-8859 文本。不要发布 HTML 邮件、富文本邮件或其他可能对纯文本邮件阅读器不透明的格式。关于语言:我们没有只使用英语的政策,但您可能通过用英语发布获得最佳结果——它是大多数列表参与者共享的语言。
Subversion 不是完美的软件。它包含错误,缺少功能,并且像任何其他软件一样有改进的空间。与大多数软件项目一样,Subversion 项目使用问题跟踪工具来管理软件中已知的未解决问题。但也许与大多数软件项目不同的是,我们试图让我们的问题跟踪器相对没有杂物。这并不是说我们不想听到关于 Subversion 问题的信息——毕竟,我们无法修复我们不知道的问题。只是我们发现管理不善的问题跟踪器弊大于利。
这封邮件几乎说明了一切(除了现在您应该在发布到 dev@ 列表之前发布到 users@ 列表)。
From: Karl Fogel <kfogel@collab.net>
Subject: Please ask on the list before filing a new issue.
To: dev@subversion.tigris.org
Date: Tue, 30 Jul 2002 10:51:24 (CDT)
Folks, we're getting tons of new issues, which is a Good Thing in
general, but some of them don't really belong in the issue tracker.
They're things that would be better solved by a quick conversation
here on the dev list. Compilation problems, behavior questions,
feature ideas that have been discussed before, that sort of thing.
*Please* be more conservative about filing issues. The issues
database is physically much more cumbersome than email. It wastes
people's time to have conversations in the issues database that should
be had in email. (This is not a libel against the issue tracker, it's
just a result of the fact that the issues database is for permanent
storage and flow annotation, not for real-time conversation.)
If you encounter a situation where Subversion is clearly behaving
wrongly, or behaving opposite to what the documentation says, then
it's okay to file the issue right away (after searching to make sure
it isn't already filed, of course!). But if you're
a) Requesting a new feature, or
b) Having build problems, or
c) Not sure what the behavior should be, or
d) Disagreeing with current intended behavior, or
e) Not TOTALLY sure that others would agree this is a bug, or
f) For any reason at all not sure this should be filed,
...then please post to the dev list first. You'll get a faster
response, and others won't be forced to use the issues database to
have the initial real-time conversations.
Nothing is lost this way. If we eventually conclude that it should be
in the issue tracker, then we can still file it later, after the
description and reproduction recipe have been honed on the dev list.
Thank you,
-Karl
以下是我们要求人们在报告 Subversion 问题或请求增强功能时遵守的政策。
首先,确保这是一个错误。如果 Subversion 的行为与您的预期不符,请查看文档和邮件列表存档,以证明它应该按您的预期方式运行。当然,如果这是一件常识性的事情,比如 Subversion 只是破坏了您的数据并导致您的显示器冒烟,那么您可以相信您的判断。但如果您不确定,请先在用户邮件列表 users@subversion.apache.org 上询问,或在 IRC irc.libera.chat,频道 #svn(网页界面 或 Matrix)上询问。
您也应该在错误追踪器中搜索,看看是否有人已经报告了这个错误。
一旦您确定这是一个错误,并且我们还没有发现它,您能做的最重要的事情就是想出一个简单的描述和重现方法。例如,如果您最初发现的错误涉及十次提交中的五个文件,请尝试只用一个文件和一次提交来重现它。重现方法越简单,开发人员就越有可能成功重现错误并修复它。
在编写重现方法时,不要仅仅用散文描述您为使错误发生所做的操作。相反,请提供您运行的命令序列及其输出的文字记录。使用剪切粘贴来完成此操作。如果涉及文件,请务必包含文件名称,甚至包含您认为可能相关的内容。最好的方法是将您的重现方法打包成一个脚本;这将对我们有很大帮助。以下是一个此类脚本的示例:repro-template.sh (适用于类 Unix 系统和 Bourne shell)或 repro-template.bat(适用于 Windows shell,由 Paolo Compieta 贡献);我们欢迎为其他系统贡献类似的模板脚本。
快速检查:您*正在*运行最新版本的 Subversion,对吧?:-) 可能这个错误已经被修复了;您应该针对最新的 Subversion 开发树测试您的重现方法。
除了重现方法之外,我们还需要您重现错误的环境的完整描述。这意味着
一旦您拥有了所有这些信息,您就可以开始编写报告了。首先清楚地描述错误是什么。也就是说,说明您期望 Subversion 如何运行,并将其与实际运行方式进行对比。虽然这个错误对您来说可能很明显,但对其他人来说可能并不明显,因此最好避免猜测。然后是环境描述和重现方法。如果您还想包括对原因的推测,甚至包含一个修复错误的补丁,那就太好了——请参阅补丁提交指南。
请将所有这些信息发送到 dev@subversion.apache.org,或者如果您已经联系过他们并被要求提交问题,请访问 问题跟踪器 并按照那里的说明操作。
感谢您。我们知道提交有效的错误报告需要很多工作,但一份好的报告可以节省开发人员数小时的时间,并使错误更有可能得到修复。
如果错误出现在 Subversion 本身,请发送邮件到 users@subversion.apache.org。一旦确认是错误,有人,可能是您,可以将其输入到 问题跟踪器 中。(或者,如果您对错误非常确定,可以直接发布到我们的开发列表 dev@subversion.apache.org。但如果您不确定,最好先发布到 users@;那里的人可以告诉您您遇到的行为是否符合预期。)
如果错误出现在 APR 库中,请将其报告到以下两个邮件列表:dev@apr.apache.org,dev@subversion.apache.org。
如果错误出现在 Neon HTTP 库中,请将其报告到:neon@webdav.org,dev@subversion.apache.org。
如果错误出现在 Apache Serf HTTP 库中,请将其报告到:dev@serf.apache.org,dev@subversion.apache.org。
如果错误出现在 Apache HTTPD 2.x 中,请将其报告到以下两个邮件列表:dev@httpd.apache.org,dev@subversion.apache.org。Apache httpd 开发者邮件列表流量很大,因此您的错误报告帖子有可能被忽略。您也可以在 https://httpd.apache.ac.cn/bug_report.html 提交错误报告。
如果错误出现在您的地毯上,请抱抱它并让它保持舒适。
问题跟踪器里程碑是 Subversion 开发人员组织工作并与彼此以及 Subversion 用户群进行沟通的重要方面。除了主要用于进行高级 问题分类 的一些里程碑外,项目的里程碑往往以反映发布版本号及其变体的名称命名。里程碑用于略微不同的目的,具体取决于问题的状态,因此了解这些区别很重要。
对于开放问题(状态为 OPEN、IN PROGRESS 或 REOPENED 的问题),里程碑表示开发人员针对该问题解决的目标 Subversion 版本。在一般情况下,我们使用 MINORVERSION-consider 形式的里程碑来表示问题解决被认为是我们希望在 MINORVERSION.0 中发布的内容。例如,我们认为可以并且应该添加到 Subversion 1.9.0 中的功能将获得 1.9-consider 里程碑。出于显而易见的原因,这些发布目标的准确性随着您展望未来的时间越长而越差,因此,鼓励用户不要将它们视为开发人员社区的具有约束力的承诺。
在任何给定时间,社区中都会有针对“下一个重大版本”的工作正在进行。随着该版本开始成型,开发人员将更好地了解哪些问题是该版本“必须具备的”(也称为“发布阻碍者”),哪些是“锦上添花”,以及哪些应该完全推迟到未来的版本。问题里程碑是用来承载这些决策结果的机制。被认为是发布阻碍者的问题将从 MINORVERSION-consider 里程碑移动到 MINORVERSION.0 里程碑;“锦上添花”将保留 MINORVERSION-consider 里程碑;而从版本中推迟的问题将根据我们是否清楚地猜测问题何时会被解决,重新设置里程碑为 ANOTHERMINORVERSION-consider 或 unscheduled。
继续前面的例子,随着 Subversion 1.9.0 版本的开发进展,开发人员将评估我们为该版本计划的功能。如果我们认为 Subversion 1.9 应该在没有该功能的情况下发布,我们将更改其里程碑从 1.9-consider 到 1.9.0;如果我们希望在有该功能的情况下发布,但不想承诺,我们将保留里程碑为 1.9-consider;如果我们知道我们不会在 1.9.x 版本系列中实现该功能,我们将重新设置该问题的里程碑为其他内容(例如 1.10-consider)。
MINORVERSION.0 里程碑的准确性非常重要,因为开发人员倾向于使用这些问题来集中他们在重大版本周期最后几天的精力。
对于已修复的问题(其状态为 RESOLVED 且解决方案为 FIXED),问题里程碑将承担新的效用:跟踪第一个包含该问题解决方案的 Subversion 版本。无论给定问题的目标版本是什么,一旦它被解决,其里程碑应该反映第一个包含该解决方案的版本的精确版本号。
对于其他已关闭的问题(那些不是“打开”的,也不是真正“修复”的),问题里程碑往往毫无意义。当问题本身实际上被忽略时,尝试维护该跟踪字段没有意义,因为它是重复的,或者因为它是一个无效或不准确的报告。
在这些状态之间转换问题时,必须小心。已解决的开放问题需要调整其里程碑,以反映将首次反映该更改的 Subversion 版本。已解决的问题如果被移植到之前的发布流,则需要调整其里程碑,以指向该之前发布的版本号。最后,已解决的问题如果被 REOPENED,则需要根据该问题是否是发布阻断问题 (MINORVERSION.0) 来重新评估其里程碑,如果不是 (MINORVERSION-consider)。在这种情况下,查看问题的更改历史记录以了解问题在被解决为已修复之前使用了哪个里程碑可能会有所帮助。
当提交问题时,它会进入特殊的里程碑 "---",表示未设置里程碑。这是一个问题在有人有机会查看它们并决定如何处理之前所处的暂存区域。
当您按里程碑排序时,未设置里程碑的问题会首先列出,而问题分类是指遍历所有 开放问题(从未设置里程碑的问题开始)的过程,确定哪些问题足够重要,需要立即修复,哪些问题可以等到下一个版本再修复,哪些问题是现有问题的重复,哪些问题已经解决等等。对于每个将保持开放状态的问题,这也意味着确保各种字段设置得当:类型、子组件、平台、操作系统、版本、关键字(如果有)等等。
以下是该过程的概述(在本例中,1.5 是下一个版本,因此紧急问题将被分配到该版本)
for i in issues_marked_as("---"):
if issue_is_a_dup_of_some_other_issue(i):
close_as_dup(i)
elif issue_is_invalid(i):
# A frequent reason for invalidity is that the reporter
# did not follow the "buddy system" for filing.
close_as_invalid(i)
elif issue_already_fixed(i):
version = fixed_in_release(i)
move_to_milestone(i, version)
close_as_fixed(i)
elif issue_unreproducible(i):
close_as_worksforme(i)
elif issue_is_real_but_we_won't_fix_it(i):
close_as_wontfix(i)
elif issue_is_closeable_for_some_other_reason(i):
close_it_for_that_reason(i)
# Else issue should remain open, so DTRT with it...
# Set priority, environment, component, etc, as needed.
adjust_all_fields_that_need_adjustment(i)
# Figure out where to put it.
if issue_is_a_lovely_fantasy(i):
move_to_milestone(i, "blue-sky")
if issue_is_not_important_enough_to_block_any_particular_release(i):
move_to_milestone(i, "nonblocking")
elif issue_resolution_would_require_incompatible_changes(i):
move_to_milestone(i, "2.0-consider")
elif issue_hurts_people_somewhat(i):
move_to_milestone(i, "1.6-consider") # or whatever
elif issue_hurts_people_a_lot(i):
move_to_milestone(i, "1.5-consider")
elif issue_hurts_and_hurts_and_should_block_the_release(i):
move_to_milestone(i, "1.5")
本文档介绍了 Subversion 开发人员如何应对安全问题。要报告问题,请参阅 安全报告说明。
Subversion 的首要任务是保护您的数据安全。为了做到这一点,Subversion 开发社区非常重视安全。我们证明这一点的一种方式是不假装自己是密码学或安全专家。与其为 Subversion 编写一堆专有的安全机制,我们更愿意教 Subversion 与那些了解该领域的人提供的安全库和协议进行互操作。例如,Subversion 将线缆加密委托给 OpenSSL 等。它将身份验证和基本授权委托给 Cyrus SASL 或 Apache HTTP Server 及其丰富的模块集合提供的那些机制。只要有可能,我们都会继续利用安全专家的知识,使用他们提供的第三方库和 API。
本文档描述了我们在收到或发现可能被归类为具有安全影响的问题时采取的步骤,旨在补充 Apache 指南,供提交者参考。
安全问题应在 private@subversion.apache.org + security@apache.org 上讨论。security@subversion.apache.org 是一个指向这两个列表的便利别名。(请注意,与 security@httpd.a.o 不同,它不是一个邮件列表,因此您无法单独订阅/取消订阅它。)
我们在以下位置发布了以前的安全公告列表:https://subversion.org.cn/security/
我们在 PMC 的私有存储库中跟踪正在进行的问题:https://svn.apache.org/repos/private/pmc/subversion/security
本文档通常可以分为三个部分,按具体程度递增
Subversion 发行版管理员使用一组在名为 release.py 的 Python 脚本中编写的步骤。此脚本可用于执行发行流程中的大多数自动化步骤。使用 -h 选项运行它以获取更多信息。
除了以下项目特定指南外,有志于成为发行版管理员的人可能还想阅读有关一般 Apache 发行策略 的信息。它们有时看起来有点拼凑,但能很好地说明一般最佳实践以及 Subversion 如何融入更大的 ASF 生态系统。
Subversion 使用“MAJOR.MINOR.PATCH”发行版编号。我们不使用“偶数==稳定,奇数==不稳定”的约定;任何未限定的三元组都表示稳定发行版
1.0.1 --> first stable patch release of 1.0 1.1.0 --> next stable minor release of 1.x after 1.0.x 1.1.1 --> first stable patch release of 1.1.x 1.1.2 --> second stable patch release of 1.1.x 1.2.0 --> next stable minor release after that
发行版的顺序是半非线性的——1.0.3 *可能* 会在 1.1.0 之后发布。但它只是“半”非线性,因为最终我们会宣布一个补丁系列失效,并告诉人们升级到下一个次要发行版,因此从长远来看,编号基本上是线性的。
数字可能有多位。例如,1.7.19 是 1.7.x 系列中的第十九个补丁发行版;它是在 1.7.2 发布三年后,在 1.7.20 发布三个月前发布的。
Subversion 发行版可以通过版本号后面的文本进行限定,这些文本都代表预发行流程中的各种步骤。从最不稳定到最稳定排序
| 限定符 | 含义 | 示例 | svn --version 的输出 |
|---|---|---|---|
| Alpha | 我们知道或预计会出现问题,但会征求感兴趣个人的测试。 | subversion-1.7.0-alpha2 | 版本 1.7.0(Alpha 2) |
| Beta | 我们预计不会出现问题,但以防万一,请谨慎。 | subversion-1.7.0-beta1 | 版本 1.7.0(Beta 1) |
| RC(发行版候选版) | 此发行版是成为最终提议版本的候选版本。如果未发现严重错误,则将删除 -rc 标签,并且此发行版的内容将被宣布为稳定版本。 | subversion-1.7.0-rc4 | 版本 1.7.0(发行版候选版 4) |
当您 'make install' subversion-1.7.0-rc1 时,它仍然像安装“1.7.0”一样安装,当然。限定符是发行版的元数据;我们希望每个后续的预发行版都覆盖前一个发行版,最终发行版覆盖最后一个预发行版。
对于工作副本构建,没有需要担心的压缩包名称,但 'svn --version' 仍然会生成特殊输出
version 1.7.1-dev (under development)
版本号是项目正在努力的下一个版本。重要的是要说明“正在开发中”。这表明构建来自工作副本,这在错误报告中很有用。
当我们希望在进入正式的 稳定期 之前,让新功能得到广泛测试时,我们会发布 alpha 和 beta 版本的 tar 包。即使有“alpha1”、“alpha2”等版本,也不需要发布任何 beta 版本;我们可以直接跳到“rc1”。但是,在某些情况下,beta 版本可能有用:例如,如果我们不确定 UI 决策,并且希望在将其固化为正式的候选版本之前获得更广泛的用户反馈。
Alpha 和 beta 版本仅供希望帮助测试的人员使用,他们理解在最终版本发布之前可能会出现不兼容的更改。签名要求由发布经理自行决定。通常,RM 每个平台只需要 1 或 2 个签名,并告诉签名者,即使他们的测试发现了一些小问题,他们仍然可以签名,只要他们认为代码足够稳定,可以供其他人进行测试。RM 应该要求签名者在签名时附上任何错误的描述,以便在发布 alpha 或 beta 版本时公布这些问题。
当 alpha 或 beta 版本公开发布时,应严厉警告分发包管理器不要打包它。请参阅 Hyrum K. Wright 的这封邮件,了解一个很好的模型。
我们的兼容性规则(详见 下方)仅在最终 x.y.0 版本获得批准并发布后才开始适用。任何出现在 trunk 或 alpha/beta/rc 预发布版本中的 API、线协议和磁盘格式都不受任何兼容性承诺的约束;如果我们找到充分的理由,我们可能会在最终版本发布之前任意更改它们。我们甚至可能完全删除我们不喜欢的接口或序列化格式。
对于持久数据(工作副本和存储库),这尤其是一个问题,因为我们可能不会在最终版本中提供升级路径——代码路径或用于旧格式的指定脚本。(当然,我们可能会为测试预发布版本的开发人员和用户提供此类脚本;但我们没有义务这样做。)因此,永远不要将预发布版本用于任何需要长期安全保存的数据。
同时,我们希望提醒读者,指出 API 设计错误的最佳时机是在它们发布并固定之前——换句话说,在初始设计和预发布阶段。
如果由于某些非代码问题(例如,打包故障)需要快速重新发布某个版本或候选版本,则可以使用相同的名称,只要 tarball 尚未 通过签名验证。但是,如果它已上传到标准分发区域并带有签名,或者重新发布是由于用户可能运行的代码更改造成的,则必须丢弃旧名称并使用下一个名称。
如果在发布候选版本 tarball 发布并宣布给用户之前丢弃了旧名称,则丢弃的名称被视为非公开版本,并且文档(例如 CHANGES 和标签的日志消息)应更新以反映这一点。(参见 1.8.7 以获取示例。)丢弃版本的标签和 tarball 保留在存储库历史记录中,但它们不受支持用于一般用途(相反,它们已知存在发布阻塞错误)。
Subversion 遵循严格的兼容性,与 APR 的指南相同(参见 https://apr.apache.org/versioning.html),另外还有一些扩展,将在后面描述。这些指南旨在确保各种形式的客户端/服务器互操作性,并确保用户在 MAJOR.MINOR Subversion 版本之间拥有清晰的升级路径。
兼容性可以跨越多个轴:从 API 和 ABI 到命令行输出格式。我们试图在修改现有架构以支持新功能的需求与尽可能支持当前用户的需求之间取得平衡。一般思路是
在同一 MAJOR.MINOR 行中不同补丁版本之间升级/降级永远不会破坏代码。它可能会导致错误修复消失/重新出现,但 API 签名和语义保持不变。(当然,语义可能会以适合错误修复的微不足道的方式发生变化,但不会以强制调整调用代码的方式发生变化。)
升级到同一主线中的新次要版本可能会导致出现新的 API,但不会删除任何 API。针对旧次要版本编写的任何代码都可以在该主线中的任何更高次要版本中使用。但是,如果新代码利用了新的 API,则之后降级可能无法正常工作。
(偶尔,会发现需要稍微修改旧 API 行为的错误。这通常只会在各种极端情况和其他不常见区域表现出来。这些更改在每个 MAJOR.MINOR 版本的 API 勘误表 中有记录。)
当主版本号更改时,所有假设都将失效。这是唯一一次可以完全重置 API 的机会,虽然我们尽量避免无故删除接口,但我们会利用它来进行一些清理。
Subversion 扩展了 APR 指南,以涵盖客户端/服务器兼容性问题。
服务器(或客户端)的补丁或次要版本发布永远不会破坏与同一主线中的客户端(或服务器)的兼容性。但是,该版本提供的新的功能可能在没有对连接另一端进行相应升级的情况下不受支持。对于更新 ra_svn 代码,请特别注意以下原则。
可以向任何元组添加字段;旧客户端将简单地忽略它们。(目前,编组实现不允许您在元组的可选部分放置数字或布尔值,但更改这一点不会影响协议。)
当向 API 调用添加信息时,我们可以使用此机制。
在建立连接时,客户端和服务器交换一个功能关键字列表。
我们可以使用此机制进行更复杂的更改,例如引入管道或从 API 调用中删除信息。
可以添加新的命令;尝试使用不支持的命令将导致错误,可以检查并处理该错误。
协议版本号可以被提升,以允许优雅地拒绝旧的客户端或服务器,或者允许客户端或服务器检测到它何时必须以旧的方式执行操作。
这种机制是最后的手段,在能力关键字难以管理时使用。
工作副本和存储库格式对于同一次要系列中的所有补丁版本都是向后和向前兼容的。它们对于同一主要系列中的所有次要版本都是向前兼容的;但是,允许次要版本创建与以前次要版本不兼容的工作副本或存储库,其中“创建”可能意味着“升级”以及“创建”。
Subversion 不发布二进制包,而是依赖于 第三方打包者 来完成。幸运的是,许多个人和公司已经自愿参与了这项工作,我们感谢他们的努力。
如果您是第三方打包者,您可能会遇到一些情况,即错误修复或其他更改对您的用户很重要,并且您希望比标准的 Subversion 发布周期更快地将它们提供给他们。或者您可能在本地维护了一组补丁,这些补丁对您的目标受众有益。如果可能,建议使用 补丁流程,并将您的更改接受并应用到主干,以便在正常的 Subversion 发布计划中发布。
但是,如果您认为您需要进行不会被 Subversion 开发者社区广泛接受的更改,或者需要提供对未发布功能的早期访问,您应该遵循以下指南。它们旨在帮助防止用户社区混淆,并使您的分发和官方 Subversion 版本尽可能成功。
首先,确保您遵循 ASF 商标政策。您需要将您的版本与标准的 Subversion 版本区分开来,以减少您的自定义版本可能造成的任何潜在混淆。
其次,考虑在公共 Subversion 存储库中创建一个分支来跟踪您的更改,并可能允许将您的自定义更改合并到主线 Subversion 中。(如果您还没有,请 申请提交访问权限。)
第三,如果您的自定义版本可能会生成与主线 Subversion 无关的错误报告,请与自定义版本的使用者保持联系,以便您可以拦截和过滤这些报告。当然,最好的选择是首先避免这种情况——您的自定义版本与主线 Subversion 的差异越大,它带来的困惑就越多。如果您必须创建自定义版本,请尽量保持它们是临时的,并且尽可能地不产生差异。
当引入新的、改进的 API 版本时,旧版本出于兼容性考虑会保留,至少保留到下一个主要版本 (2.0.0) 发布之前。但是,我们会将旧版本标记为已弃用,并指向新版本,以便人们知道尽可能地使用新 API。弃用时,请提及引入弃用后的版本,并指向新 API。如果可能,请用新 API 的差异替换旧 API 文档。例如
/**
* Similar to svn_repos_dump_fs3(), but with a @a feedback_stream instead of
* handling feedback via the @a notify_func handler
*
* @since New in 1.1.
* @deprecated Provided for backward compatibility with the 1.6 API.
*/
SVN_DEPRECATED
svn_error_t *
svn_repos_dump_fs2(svn_repos_t *repos,
svn_stream_t *dumpstream,
svn_stream_t *feedback_stream,
svn_revnum_t start_rev,
svn_revnum_t end_rev,
svn_boolean_t incremental,
svn_boolean_t use_deltas,
svn_cancel_func_t cancel_func,
void *cancel_baton,
apr_pool_t *pool);
当主要版本号发生变化时,一系列中“最佳”的新 API 通常会替换所有以前的 API(假设它包含了它们的功能),并且它将采用原始 API 的名称。因此,在 1.1.x 中将 'svn_repos_dump_fs' 标记为已弃用并不意味着 2.0.0 没有 'svn_repos_dump_fs',它只是意味着该函数的签名将不同:它将具有 1.1.x 中 svn_repos_dump_fs2(或 svn_repos_dump_fs3,或其他)所持有的签名。带数字后缀的名称会消失,并且只有一个(闪亮的新)svn_repos_dump_fs 再次出现。
这种替换策略的一个例外是,当旧函数的名称完全不令人满意时。弃用是一个修复它的机会:我们给新 API 一个全新的名称,将旧 API 标记为已弃用,指向新 API;然后在主要版本更改时,我们删除旧 API,但不会将新 API 重命名为旧名称,因为它的新名称很好。
小版本和主版本发布在发布之前会经历一个稳定期,并在发布后进入维护(修复 bug)模式。要开始发布流程,我们会基于最新的主干创建一个“A.B.x”分支。
新 A.B.0 版本的稳定期通常持续四周,这使我们能够进行保守的 bug 修复并发现重大问题。稳定期从版本为 A.B.0-rc1 的发布候选包开始。随着阻塞性 bug 的修复,可能会发布更多发布候选包;例如,如果发现一组语言绑定出现问题,那么在修复这些语言绑定后,谨慎起见,应该发布一个新的发布候选包,以便对这些语言绑定进行测试。
创建 A.B.x 分支后,永远不会直接向其提交源代码更改;更改会在经过投票后,通过下一节中描述的过程,从主干回移植到 A.B.x 分支。
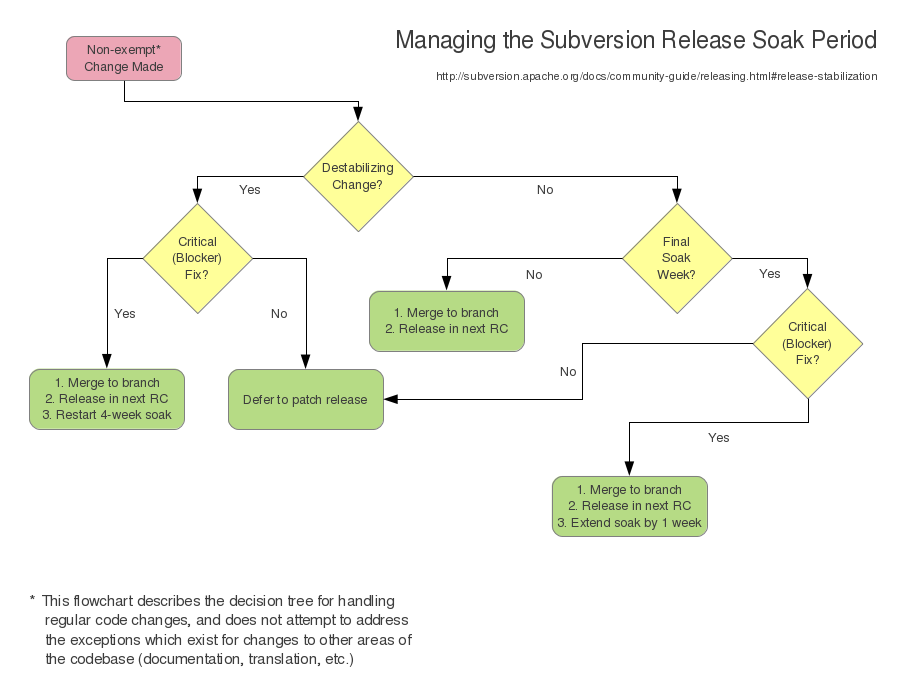
在稳定期的最后一周开始时,如果自上次发布候选包以来有任何待处理的重大更改,则应该发布一个新的发布候选包。稳定期的最后一周保留用于修复严重 bug;修复次要 bug 应该推迟到 A.B.1 版本。严重 bug 指的是非边缘情况下的崩溃、数据损坏问题、重大安全漏洞或其他同样严重的问题。
在某些情况下,稳定期将延长
svn-soak-management.png
如果必须进行潜在的破坏性更改才能修复 bug,则整个四周的稳定期将重新开始。潜在的破坏性更改是指可能以不可预测的方式影响 Subversion 的许多部分,或涉及添加大量新代码的更改。任何不兼容的 API 更改(只有在新的版本是 A.0.0 版本时才允许)都应该被视为潜在的破坏性更改。
如果在稳定期的最后一周进行了严重 bug 修复,则最后一周将重新开始。最终的 A.B.0 版本始终与一周前发布的发布候选包相同(以下讨论的例外情况除外)。
A.B.0 版本发布后,当 bug 修复需要时,将发布补丁版本(A.B.1、A.B.2 等)。补丁版本不需要四周的浸泡,因为只有保守的更改会进入该分支。
某些类型的提交可以进入 A.B.0,而不会重新开始浸泡期,或者进入以后的版本,而不会影响测试计划或发布日期
无需投票
需要投票
仅影响 tools/、packages/ 或 bindings/ 的任何更改。
对打印输出的更改,例如错误和使用消息,只要格式字符串“%”代码及其参数未被触碰。
注意:对消息翻译更改的要求比对 C 代码中的文本消息的要求更宽松。允许在 .po 文件中更改格式说明符,因为它们的有效性可以通过机械方式检查(使用 GNU gettext 的 msgfmt 上的 -c 标志)。如果使用 GNU gettext,这将在构建时完成。
当然,核心代码更改需要投票,并重新开始浸泡或测试周期,否则更改可能未经充分测试。
对 A.B.x 行的更改必须首先在 A.B.x/STATUS 文件中提出。每个提案都包含一个简短的标识块(例如,主干或相关行提交的修订号,或者可能是问题编号)、对更改的简要描述、对更改应在 A.B.x 中的原因的最多一行理由,可能还有一些注释/关注点,最后是投票。注释和关注点旨在简要总结以帮助读者了解情况。不要使用 STATUS 文件进行实际讨论;请使用 dev@。
以下是一个示例,可能与条目一样复杂
* r98765 (issue #56789)
Make commit editor take a closure object for future mindreading.
Justification:
API stability, as prep for future enhancement.
Branch: 1.8.x-r98765
Notes:
There was consensus on the desirability of this feature in
the near future; see thread at http://... (Message-Id: blahblah).
Merge with --accept=mc.
Concerns:
Vetoed by jerenkrantz due to privacy concerns with the
implementation; see thread at http://... (Message-Id: blahblah)
Votes:
+1: ghudson, bliss
+0: cmpilato
-0: gstein
-1: jerenkrantz
任何人都可以投票,但只有完整提交者和相关区域的部分提交者具有约束力投票。当提交者投出非约束力投票(例如,部分提交者投票赞成其提名区域之外的更改)时,他们应该将其投票注释为非约束力,如下所示
* r31833
svndumpfilter: Don't match prefixes to partial path components.
Fixes #desc4 of issue #1853.
Votes:
+1: danielsh, hwright
+1 (non-binding): stylesen
这种区别在各种投票中都有体现——回退投票、发布投票以及传说中的因未能达成共识而产生的投票——但原因各不相同。在发布投票中,这种区别在法律上是发布进入 ASF 法律保护范围的必要条件,而在回退投票中,它更接近于一种咨询性的区别。毕竟,如果有人出于正当理由对变更投了 -1 票,他们的认证并不重要;如果他们的分析是正确的,变更就不会被回退。同样,如果一个变更没有获得所需的绑定 +1 票数,但有一些非绑定 +1 票,这可能有助于它获得批准。
换句话说,回退流程的目的是确保不稳定的变更不会进入补丁版本。投票通过强制每个变更进行一定程度的审查来实现这一目的。由于业力不可转让,我们用绑定投票来衡量“审查程度”——但与以往一样,任何人都可以对流程进行输入并得到倾听。
投票者对变更的意见被编码为 +1、-1、+0 或 -0。
定义“否决权”或参考定义
如果你投了否决票(即 -1),请在“问题”字段中说明原因,并包含列表讨论的 url/消息 ID(如果有)。如果你在提交否决票时没有找到相关讨论,你可以在之后添加链接。
-0 票意味着你对变更有些反对——在 dev@ 上说明你的理由,或在括号中进行总结——但不会阻碍共识。
对变更投 +1 票并不仅仅意味着你原则上同意它。这意味着你已经彻底审查了变更,并认为它正确且尽可能地没有破坏性。当它被提交到发布分支时,日志消息将包含所有投票支持它的人员的姓名,以及原始作者和提交变更的人员。所有这些人被认为对 bug 负有同等的责任。提交者被信任知道他们不知道什么,并且不会轻易投 +1 票。
如果你已经审查了一个补丁,并且喜欢它,但有一些保留意见,你可以写“+1(概念)”,然后在列表中询问你关心的问题。如果你喜欢这个想法,但没有仔细审查补丁,你可以写“+0”。这些投票都不计入总数,但它们可以用来追踪关注变更的人员,他们可能愿意花更多时间在上面。
对于非 LTS(“常规”)发布线,更改需要两个 +1 才能获得批准,并且不能有否决票。(只有绑定投票有效;见上文。)
对于LTS 发布线,更改需要三个 +1 才能获得批准,并且不能有否决票。(只有绑定投票有效;见上文。)
尽管有上述规定,对于任何发布线,仅影响非核心代码(例如,tools/、packages/、bindings/、测试脚本等)且不影响构建系统的更改,可以由该区域的完整提交者或部分提交者提供一个 +1,以及任何其他提交者提供至少一个 +0 或“概念 +1”,并且没有否决票。
目标是让至少两双眼睛查看更改,而不强求每个审阅者都拥有与区域维护者相同的专业知识。这样,一个人可以审查更改的一般合理性、准确的注释、明显的错误等,而不必强迫自己断言“是的,我理解这些更改的每一个细节,并且已经测试过它们。”
在 STATUS 中提议更改之前,您应该尝试将其合并到分支中,以确保它不会产生合并冲突。如果出现冲突,请从发布分支创建一个新的临时分支,并将您的更改合并到该分支,并解决冲突。该分支应命名为 A.B.x-rYYYY,其中 YYYY 是您在 STATUS 文件中更改的第一个修订版。在 STATUS 文件中添加一条关于临时分支存在的注释,形式为 Branch: A.B.x-rYYYY 或 Branch: ^/subversion/branches/A.B.x-rYYYY 标题(使用此确切形式;脚本会解析它)。如果更改涉及进一步的工作,您可以将这些修订版合并到分支中。当此更改的条目从 STATUS 中删除时,此临时分支也应删除,以避免使 /branches 目录混乱。
在极少数情况下,需要对 A.B.x 分支进行更改,而该更改不是从主干回退的更改,也会使用临时分支。
如果您提名的条目会导致合并冲突,直到另一个提名被合并,请在提名中注明这一点。在条目中添加一个“Depends:”标题;这将使每小时的“检测具有合并冲突的提名”构建机器人作业保持绿色。(“Depends:”标题的值不会被解析。)
tools/dist/nominate.pl 脚本(在主干中)自动执行添加新提名的过程。同一个脚本还具有一个 REPL 循环,可以帮助审查提名和投票;请参阅 tools/dist/README.backport(在主干中)。
注意:关于临时分支的 STATUS 更改,包括投票,始终保留在主发布分支上。
在实际发布之前,请向翻译人员发送电子邮件,要求他们更新 .po 文件。从 trunk 中的 COMMITTERS 文件中获取他们的电子邮件地址,可以使用以下命令:
sed -e '/^ *Translat.*:$/,/:$/!d' -e 's/^ *[^ ]* *\([^>]*>\).*/\1/;t;d' COMMITTERS
包含由以下命令生成的翻译状态报告:
./tools/po/l10n-report.py
这应该在所有本地化字符串在发布版本中最终确定后完成,但要足够提前,以便翻译人员有时间完成他们的工作。作为经验法则,请至少提前一周(最好更早)发送通知,以便在预定的发布日期之前完成。如果更改了许多字符串(例如,从新分支发布的第一个版本),则需要更多时间。
因此,发布分支已经稳定,您正在准备发布版本。发布过程的详细信息由 release.py 辅助脚本自动执行。要运行此脚本,您需要一个 Subversion trunk 工作副本。运行 release.py -h 以获取可用子命令的列表。
在您实际发布存档之前,您需要设置一个白盒发布环境。此环境必须包含一些构建工具的原始版本。
重要的是,您不要使用发行版提供的这些软件版本,因为它们通常会以不可移植的方式进行修补(例如,Debian 的 libtool 修补程序:#291641,#320698)。tools/dist/release-lines.yaml 中给出的版本号通常应该重新考虑,并在发布 A.B.0 版本之前增加到最新的稳定上游版本。在 A.B.x 系列中更改版本应该谨慎考虑。
Autoconf、Libtool 和 SWIG:选择一个目录来包含您用于 Subversion RM 任务的特殊构建工具 - 例如 /opt/svnrm。使用 release.py build-env 命令配置、构建和安装这三部分软件。
mkdir -p /opt/svnrm && cd /opt/svnrm && $SVN_SRC_DIR/tools/dist/release.py build-env X.Y.Z
发布脚本还需要以下命令可用:pax、xgettext、m4 和 python -c 'import yaml'。
从您的操作系统软件包中安装这些。 (在 Debian 系统上,应该是 apt install pax gettext m4 python-yaml subversion。)
发布前:
创建压缩包:运行
./release.py roll X.Y.Z 1234当 release.py 完成后,您将在 /opt/svnrm/deploy 目录中找到压缩包。
测试一个或两个压缩包
a) tar zxvf subversion-X.Y.Z.tar.gz; cd subversion-X.Y.Z
b) ./configure
See INSTALL, section III.B for detailed instructions on
configuring/building Subversion.
If you installed Apache in some place other than the default, as
mentioned above, you will need to use the same
--prefix=/usr/local/apache2 option as used to configure Apache.
You may also want to use --enable-mod-activation, which will
automatically enable the required Subversion modules in the
Apache config file.
c) make
d) make check
e) make install (this activates mod_dav)
f) make davcheck
For this, start up Apache after having configured according to
the directions in subversion/tests/cmdline/README.
Make sure, that if you maintain a development installation of
apache, that you check the config file and update it for the
new release area where you're testing the tar-ball.
(Unless you rename the tree which gets extracted from the
tarball to match what's in httpd.conf, you will need to edit
httpd.conf)
g) make svncheck
First, start up svnserve with these args:
$ subversion/svnserve/svnserve -d -r \
`pwd`/subversion/tests/cmdline
-d tells svnserve to run as a daemon
-r tells svnserve to use the following directory as the
logical file system root directory.
After svnserve is running as a daemon 'make svncheck' should run
h) Then test that you can check out the Subversion repository
with this environment:
subversion/svn/svn co https://svn.apache.org/repos/asf/subversion/trunk
i) Verify that the perl, python, and ruby swig bindings at least compile.
If you can't do this, then have another developer verify.
(see bindings/swig/INSTALL for details)
Ensure that ./configure detected a suitable version of swig,
perl, python, and ruby. Then:
make swig-py
make check-swig-py
sudo make install-swig-py
make swig-pl
make check-swig-pl
sudo make install-swig-pl
make swig-rb
make check-swig-rb
sudo make install-swig-rb
j) Verify that the javahl bindings at least compile.
If you can't do this, then have another developer verify.
(see subversion/bindings/javahl/README for details)
Ensure that ./configure detected a suitable jdk, and then
possibly re-run with '--enable-javahl', '--with-jdk=' and
'--with-junit=':
make javahl
sudo make install-javahl
make check-javahl
k) Verify that the ctypes python bindings at least compile.
If you can't do this then have another developer verify.
(see subversion/bindings/ctypes-python/README for details)
Ensure that ./configure detected a suitable ctypesgen, and
then possibly re-run with '--with-ctypesgen':
make ctypes-python
sudo make install-ctypes-python
make check-ctypes-python
l) Verify that get-deps.sh works and does not emit any errors.
./get-deps.sh
使用 GnuPG 签署发布版本
使用 release.py 签署发布版本release.py sign-candidates X.Y.Z这将为您运行以下命令的等效命令
gpg -ba subversion-X.Y.Z.tar.bz2
gpg -ba subversion-X.Y.Z.tar.gz
gpg -ba subversion-X.Y.Z.zip
并将 gpg 签名追加到相应的 .asc 文件。
Subversion 操作
使用反映最终发布版本的 svn_version.h 创建标签。您可以使用
release.py create-tag X.Y.Z 1234
注意:请始终创建标签,即使是发布候选版本。
create-tag 将为原始分支中的 STATUS 和 svn_version.h 文件增加版本号。如果您刚刚发布了 1.0.2,那么这两个文件都应该具有 1.0.3 的正确值,依此类推。
将压缩包、签名和校验和提交到 https://dist.apache.org/repos/dist/dev/subversion。有一个 release.py 子命令可以自动执行此步骤
release.py post-candidates 1.7.0
宣布发布候选版本可供测试和签署
向 dev@ 列表发送电子邮件,类似于 此邮件
Subject: Subversion X.Y.Z up for testing/signing The X.Y.Z release artifacts are now available for testing/signing. Please get the tarballs from https://dist.apache.org/repos/dist/dev/subversion and add your signatures there. Thanks!
调整 #svn-dev 上的主题以提及“X.Y.Z 可供测试/签署”
更新问题跟踪器以具有适当的版本/里程碑。如果发布新的次要版本,则应添加 1.MINOR.x 的版本。所有发布版本都应添加下一个发布版本的版本(即 1.MINOR.x+1)。如果您没有权限执行此操作,请在 IRC 上询问或向 dev@ 列表发送电子邮件。
Subversion 发行版通过全球 内容分发网络 (CDN) 分发。(这取代了 2021 年底之前的 ASF 镜像网络。不过,可能存在其他组织选择继续镜像 ASF 发行版。)
重要的是,最终用户能够验证他们下载的源代码包的真实性。校验和足以检测下载过程中的损坏,但为了防止恶意个人或镜像操作员分发替换包,每个源代码包都必须由 Subversion PMC 成员进行 加密签名。这些签名使用每个提交者的私有 PGP 密钥完成,然后与发行版一起发布,以便最终用户可以验证下载的包的完整性。
在 Subversion 发行版正式公开之前,它需要
在创建初始的 tarball 集时,发行版管理员还会创建第一组签名。虽然 tarball 本身可能是在 people.apache.org 上构建的,但重要的是签名不要在那里生成。签署 tarball 需要私钥,并且强烈建议不要在 ASF 硬件上存储私钥。签署 tarball(使用以下过程)后,发行版管理员应将签名上传到初步分发位置,并将它们放置在与 tarball 相同的目录中。
鼓励 PMC 成员以及热情的社区成员从初步分发位置下载 tarball,运行测试,然后提供他们的签名。这些签名的公钥应通过 id.apache.org 包含在 ASF LDAP 实例中。(Subversion 提交者和 PMC 成员的当前公钥列表 是每天从 LDAP 自动生成的。)鼓励发行版管理员在宣布发行版之前至少等待 5 天,以便任何测试该版本的人员在宣布之前完成签署发行版。
签署一个 tarball 文件意味着你对它做出了一些断言。在宣布你的签名时,请在邮件中说明你采取了哪些步骤来验证 tarball 文件是否正确,例如,验证其内容是否与存储库中的正确标签一致。在所有 RA 层和 FS 后端运行 make check 也是一个好主意,以及构建和测试绑定。
要获取发布候选版本,请检出一个 https://dist.apache.org/repos/dist/dev/subversion 的工作副本。验证发布经理对 tarball 文件的 PGP 签名。release.py 自动执行此步骤。
release.py get-keys
release.py --target /path/to/dist/dev/subversion/wc check-sigs 1.7.0-rc4
验证、提取和测试 tarball 文件后,你应该使用 gpg 创建一个带装甲的独立签名来进行签名。要将你的签名附加到 .asc 文件,请使用类似以下的命令:
gpg -ba -o - subversion-1.7.0-rc4.tar.bz2 >> subversion-1.7.0-rc4.tar.bz2.ascrelease.py 脚本可以自动执行此步骤。
release.py --target /path/to/dist/dev/subversion/wc sign-candidates 1.7.0-rc4
添加你的签名后,将本地修改的 .asc 文件提交到 dist.apache.org 存储库。
如果你下载并测试了一个 .tar.bz2 文件,你可以对具有相同内容的 .tar.gz 文件进行签名,而无需单独下载和测试它。诀窍是提取 .bz2 文件,并使用 gzip 对其进行打包,如下所示:
bzip2 -cd subversion-1.7.0-rc4.tar.bz2 \
| gzip -9n > subversion-1.7.0-rc4.tar.gz
生成的与发布经理生成的文件应该相同,因此可以按照上述方法进行签名。要验证文件是否相同,可以使用校验和或发布经理的签名,两者都应该与 tarball 文件一起提供。
但是,如果校验和不相同,并不一定意味着文件签名错误或文件被篡改。很可能是你没有与发布经理相同的 gzip 版本。
在创建 tarball 文件,以及创建和验证所有签名后,发布准备就绪。本节概述发布 Subversion 版本所需的步骤。
Subversion 工件通过全球 内容分发网络 (CDN) 分发。源代码 下载页面 自动帮助用户选择合适的下载链接。我们通常只在项目的发布目录中托管支持的发布线上的最新稳定版本,而所有以前的 Subversion 版本都可以在 存档 中找到。
将发布版本上传到 CDN
release.py move-to-dist 1.7.0这将把 tarballs、签名和校验和从 ^/dev/subversion 移动到 ^/release/subversion。内容交付网络 (CDN) 大约需要 15 分钟才能获取新版本。存档也会自动获取该版本。虽然运行 move-to-dist 会移动签名文件,但提交者仍然可以将新的签名提交到 ^/release/subversion;但是,这些签名需要 15 分钟才能出现在 CDN 上。任何此类签名除非在提交后 15 分钟内,否则不能包含在发布公告中。
此时,该版本可能已公开可用,但最好还是在 CDN 获取该版本之前不要发布公告。在 15 分钟时间过去后,给 CDN 足够的时间同步,发布经理将发送公告并发布对 Subversion 网站的更改,如下所述。
这也是清理 ^/release/subversion 中任何旧版本的好时机;该目录中只应包含每个受支持发布系列的最新版本。在 ^/release/subversion 中可用至少 24 小时的版本将继续在存档中可用。您可以使用以下命令清理旧版本
release.py clean-dist
在 reporter.apache.org 上提交新版本的版本号。以下命令
curl -u USERNAME "https://reporter.apache.org/addrelease.py?date=`date +%s`&committee=subversion&version=VERSION&xdate=`date +%F`"将添加该版本,它可能应该添加到 release.py 中。
即使以下步骤指示直接更新已发布的网站,您也可以在 ^/subversion/site/staging 上准备更改。在这种情况下
从 ^/subversion/site/publish 进行追赶合并。
将任何更改提交到 ^/subversion/site/staging 并在 https://subversion-staging.apache.org 上检查结果。
准备好发布时,将更改合并回 ^/subversion/site/publish(查看合并,以防 staging 上有其他尚未合并的更改)。
对于任何版本,包括预发布版本(alpha/beta/rc)
编辑 ^/subversion/site/publish/download.html 以记录最新版本。使用 release.py write-downloads 生成表格。如果这是稳定版本,请更新 [version] 或 [supported] ezt 宏定义(例如 [define version]1.7.0[end]);如果这是预发布版本,请取消注释 <div id="pre-releases">;如果这是使预发布版本过时的 1.x.0 版本,请将其重新注释掉。
在 ^/subversion/site/publish/news.html 中添加新的新闻项目以宣布该版本。将相同的项目添加到 ^/subversion/site/publish/index.html 上的新闻列表中,并从该页面中删除最旧的新闻项目。使用 release.py write-news 生成模板新闻项目,然后对其进行自定义。在新闻项目中,有一个部分应该包含指向公告邮件的链接。目前它已注释掉,该链接将在稍后添加。如果在发布日期之前生成了模板,请检查日期是否正确。
此外,如果这是稳定版本 X.Y.Z(不是 alpha/beta/rc)
在 ^/subversion/site/publish/doap.rdf 上列出新版本
每个受支持的次要版本应该有一个 <release> 部分,其中 <created> 和 <revision> 更新为当前发布日期和补丁版本号。不要更改文件中的任何其他内容(特别是 <Project> 下的 <created> 是 Subversion 项目创建的日期)。
在 ^/subversion/site/publish/docs/release-notes/release-history.html 上列出新版本
此外,如果这是新的次要版本 X.Y.0
更新 ^/subversion/site/publish/docs/release-notes/index.html 的“支持版本”部分中的社区发布支持级别
更新 release.py 中的 supported_release_lines,必要时删除旧行。
从 ^/subversion/site/publish/docs/release-notes/X.Y.html 中删除“草稿”警告
在 ^/site/publish/docs/api/X.Y 和 ^/site/publish/docs/javahl/X.Y 中创建或更新版本化的文档快照,并确保这些目录的同级目录中的 "latest" 符号链接始终指向最新发布系列的目录。
示例
VER=1.12 DOCS_WC=~/src/svn/site/staging/docs TAG_BUILD_DIR=~/src/svn/tags/$VER.x/obj-dir cd $TAG_BUILD_DIR make doc cp -a doc/doxygen/html $DOCS_WC/api/$VER cp -a doc/javadoc $DOCS_WC/javahl/$VER for D in $DOCS_WC/api $DOCS_WC/javahl; do svn add $D/$VER rm $D/latest && ln -s $VER $D/latest done svn ci -m "In 'staging': Add $VER API docs." $DOCS_WC/api $DOCS_WC/javahl
更新索引页面 docs/index.html#api 上的 API 文档链接。
在发布日期将修改提交到“publish”(或将它们从“staging”合并到“publish”)。
新的次要版本(编号为 1.x.0)可能附带新闻稿。所有关于预期新闻稿的详细信息都在 private@ 列表中处理,并与 press@a.o 协调。
根据经验,在 浸泡开始时 在 private@/press@ 上启动一个线程;最好给 press@ 太长的预警时间,而不是太短的时间。
编写发布公告,参考以前的公告以获得指导。请记住在公告中包含 URL 和校验和!release.py write-announcement 子命令创建一个模板公告,可以根据具体情况进行自定义。如果发布修复了安全问题,请传递 --security 标志,以便在输出中生成正确的主题、抄送和描述。
如果社区支持级别随着此版本而改变,请确保在使用它生成公告之前更新 release.py 中的 recommended_release 变量。
请从你的 @apache.org 邮箱地址发送公告。(如果从其他地址发送到 announce@,邮件将会被退回。为了获得最佳效果,请遵循 提交者邮箱 页面上的说明,并通过官方邮件中继发送你的邮件。)确保你的邮件程序不会将 URL 跨行换行。
注意:我们在发布公告之前更新网站,以确保发布公告中的所有链接都是有效的。发布公告后,网站上会添加指向发布公告邮件的链接。
有两个 announce@ 邮件列表发布发布公告:Subversion 项目的 announce@subversion.apache.org 列表和 ASF 范围的 announce@apache.org 列表。你的邮件可能被 ASF 范围的 announce@ 列表拒绝。这会生成一个主题为 Returned post for announce@apache.org 的审核通知。要求邮件列表软件拒绝邮件的审核员可能忘记在拒绝邮件中签名,导致拒绝匿名,拒绝理由可能无效。无论如何,保持冷静,将拒绝转发到 dev@ 邮件列表,以便项目可以讨论是否需要采取任何措施。(如果需要,可以通过 announce-owner@ 联系 announce@ 邮件列表审核员。)
更新各种与 Subversion 相关的 IRC 频道中的主题,例如 libera.chat 上的 #svn 和 #svn-dev。
如果这是 X.Y.0 版本,请更新任何已更改支持状态的分支的 STATUS 文件顶部的社区支持级别。这通常是 X.Y.x/STATUS、X.$((Y-1)).x/STATUS,如果新版本是 LTS 版本,则也是最旧支持的 LTS 分支的 STATUS 文件。
更新 ^/subversion/site/publish/news.html 和 ^/subversion/site/publish/index.html,取消注释并添加指向发布公告邮件的链接。
现在是发布经理去享受他最喜欢的饮料的时候了。
每个新的主要版本和次要版本都会创建一个新的发布分支。例如,在准备发布 2.0.0 版本或 1.3.0 版本时,会创建一个新的发布分支。但是,在准备发布 1.3.1(补丁版本增量)时,将使用在 1.3.0 版本时创建的发布分支。
如果你正在准备发布补丁版本,那么就没有发布分支需要创建。你只需从当前次要版本系列发布分支中继续进行。
需要创建新的发布分支的时间点最好说是模糊的。一般来说,我们有一个每 6 个月发布一个新的次要版本的软计划。因此,在之前的次要版本发布大约 4 个月后,是开始提议分支的好时机。但请记住,这很灵活,取决于正在开发的功能。
查看路线图。在分支之前是否需要解决任何未完成的项目?
查看现有的稳定分支的 STATUS 文件,以查找未完成的 -0 和 -1 票。是否有将要包含在新分支中的代码遭到反对?(即使是,也不应该阻止分支,但应该开始讨论,以便在发布滚动分支之前解决问题。)
进行任何树级机械更改。(非机械更改应该在更早的时候完成,以便进行审查。)这将简化以后的合并。示例包括去除尾部空格和阻止错误泄漏以及修复 C 头文件中的不变式(另一个案例)和代码搜索和替换。(这也是进行其他定期维护任务的好时机,例如静态分析。)
审查新的和更改的 API 的设计和样式(例如 Doxygen 标记、未记录的参数、弃用、公共/私有状态等)。
运行与现有的次要版本兼容性测试。
一旦人们同意应该创建一个新的发布分支,发布经理将使用以下过程之一创建它(将 A.B 替换为您正在准备的版本,例如 1.3 或 2.0)。
tools/dist/release.py 可以自动化创建发布分支的大部分工作。
在空目录中运行它,它将在其中进行一些临时签出。
release.py --verbose create-release-branch A.B.0
如果之前没有完成,请为项目网站创建发布说明模板。
release.py --verbose write-release-notes A.B.0 > .../docs/release-notes/A.B.html svn add .../docs/release-notes/A.B.html svn ci -m "Add release notes template." .../docs/release-notes/A.B.html
本节中的大多数步骤都可以通过 tools/dist/release.py 自动化——见上文——但这里记录了这些步骤,以防发布经理想要手动执行它们。
使用服务器端复制创建新的发布分支。
svn cp ^/subversion/trunk \
^/subversion/branches/A.B.x \
-m "Create the A.B.x release branch."
编辑 trunk 上的 subversion/include/svn_version.h 并增加其中的版本号。不要提交这些更改。
主干上的版本号始终反映即将发布的版本的主要/次要版本,该版本紧随您刚刚创建分支的版本(例如,2.0.x 分支的版本号为 2.1.0,1.3.x 分支的版本号为 1.4.0)。
在主干上编辑 subversion/bindings/javahl/src/org/apache/subversion/javahl/NativeResources.java 并增加 SVN_VER_MINOR 的值。暂时不要提交这些更改。
在主干上编辑 subversion/tests/cmdline/svntest/main.py 并增加 SVN_VER_MINOR 的值。暂时不要提交这些更改。
在主干上编辑 CHANGES,为即将发布的版本添加一个新部分(如果尚未存在),并为未来将要发布的下一个次要版本添加一个新部分。每个部分都以
Version A.B.0
(?? ??? 20XX, from /branches/A.B.x)
https://svn.apache.org/repos/asf/subversion/tags/A.B.0
目前请将发布日期留空。它将一直保持这种状态,直到发布时间。
提交这些更改,并使用类似以下内容的日志消息
Increment the trunk version number to A.$((B+1)), and introduce a new CHANGES
section, following the creation of the A.B.x release branch.
* subversion/include/svn_version.h,
subversion/bindings/javahl/src/org/apache/subversion/javahl/NativeResources.java,
subversion/tests/cmdline/svntest/main.py
(SVN_VER_MINOR): Increment to $((B+1)).
* CHANGES: New section for A.$((B+1)).0.
在发布分支上创建一个新的 STATUS 文件。
确保所有 buildbot 构建器都在构建新的发布分支。
在 https://svn.apache.org/repos/infra/infrastructure/buildbot/aegis/buildmaster/master1/projects/subversion.conf 中的 MINOR_LINES 列表中添加 A.B。
创建一个模板发布说明文档,site/publish/docs/release-notes/A.B.html
请具有适当访问权限的人员将 A.B.x 分支添加到 回溯合并机器人 中。
确定发布是常规发布还是 LTS 发布,并在 tools/dist/release-lines.yaml 中的 lts_release_lines 中为 release.py 记录该决定。
回溯合并机器人每天晚上在 svn-qavm1 机器上运行,在 svnsvn 本地用户帐户下,使用 svn-role Subversion 帐户名称进行提交。
此配置目前需要具有机器管理员访问权限的人员来管理分支集的更改。
机器人会合并每个分支 A.B.x 上已批准的回溯,这些分支在 ~svnsvn/src/svn/A.B.x 中存在 WC 目录。
那里的检出是通过运行(作为 svnsvn 用户,例如使用 sudo)类似以下内容的内容创建的
svn checkout --depth=empty https://svn-master.apache.org/repos/asf/subversion/branches ~svnsvn/src/svn svn up ~svnsvn/src/svn/A.B.x # for each supported branch
仓库 URL 为 svn-master.a.o,因为回溯合并器在循环中运行 svn ci && svn up,并假设 svn up 会将其更新到刚刚提交的修订版。当从镜像更新时,这并非保证(并且 svn.a.o 可能指向镜像)。buildbot 从属服务器也出于相同原因执行此操作。
每个分支都在 WC 根目录的子目录中。要添加新分支,请使用 svn up 填充源树。
sudo -H -u svnsvn svn up ~svnsvn/src/svn/A.B.x
要删除不再支持的分支,请使用 svn up -r0
sudo -H -u svnsvn svn up -r0 ~svnsvn/src/svn/Z.Z.x
有关设置的更多说明,请参见 machines/svn-qavm1/ 和 Subversion PMC 的 私有仓库。在 machines/ 的历史记录中,还有一些关于以前版本的历史记录。
CHANGES 文件是项目的变更日志文件。在发布之前,必须将其更新以列出自上次发布以来的所有更改。
下面,我们描述了手动流程。有关部分自动化的信息,请参见
release.py write-changelog
对于补丁发布,这相当容易:您只需要遍历自上次“黄金”修订版以来的分支的提交日志,并记录所有有趣的合并。对于次要和主要版本,这更复杂:您需要遍历自上次发布分支分叉以来的主干上的提交日志,并记录所有更改。这是相同的过程,但要长得多,而且有点复杂,因为它涉及过滤掉已经回溯到以前的发布分支并从那里发布的更改集。
请记住,CHANGES 应始终在主干上进行编辑,然后在必要时合并到发布分支。所有发布的所有更改都记录在主干上的 CHANGES 文件中非常重要,这既是为了将来参考,也是为了确保未来的发布分支包含所有先前更改日志的总和。
每项变更的要点应保持简洁,最好不超过一行。有时这可能是一个挑战,但它确实提高了文档的整体可读性。问问自己:*如果描述需要超过一行,也许我太详细了?*
运行 svn log --stop-on-copy ^/subversion/branches/A.B.x。这将显示对 A.B.x 线的所有更改,包括对 A.B.x 分支的回退。然后,您需要删除已在先前主要/次要分支的微版本中发布的更改日志。在先前发布的分支上运行 svn log -q --stop-on-copy,然后编写一个脚本解析 revnums 并将其从您的主要日志输出中删除。(Karl 和 Ben 过去使用 emacs 宏来完成此操作,但建议我们编写一个更通用的脚本。)(更新:现在,svn mergeinfo --show-revs eligible 应该简化获取相关修订集的过程——使用次要分支作为源,使用先前的次要分支作为目标。)
从最旧到最新的顺序阅读该日志,并在阅读时总结要点。诀窍在于知道要写多少细节:您不想提及每一个微小的提交,但也不想过于笼统。在开始新的部分之前,阅读几页 CHANGES 文件,以确定您的过滤级别,以保持一致性。
作为 发布稳定 的一部分,应在将错误修复移植到发布分支时更新 CHANGES。通常,如果您将修订或修订组(即 STATUS 中的项目)合并到发布分支,您还应在主干上将项目添加到 CHANGES,遵循上面概述的相同准则。然后,在发布补丁版本时,此列表将合并到发布分支。
实际上,每次将修复程序回退到发布分支时,CHANGES 不会更新。通常,发布经理会将更新 CHANGES 作为发布补丁版本的第一个步骤之一。
获取应在 CHANGES 中提及的回退列表的一种便捷方法是使用与填充 Subversion 网站上的 即将发布的补丁版本 相同的工具。这是 https://svn.apache.org/repos/asf/subversion/site/tools 中的 upcoming.py 脚本。在当前工作目录是次要分支的工作副本的根目录时运行它。
翻译被分为两个领域。首先,是翻译发送给连接客户端的服务器消息。这个问题目前已被搁置。其次是翻译客户端及其库。
gettext 包提供翻译消息的服务。它使用 xgettext 工具从源代码中提取字符串进行翻译。这是通过提取 _()、N_() 和 Q_() 宏的参数来实现的。_() 用于允许函数调用的上下文中(通常是除静态初始化器之外的所有内容)。N_() 用于 _() 不适用的任何地方。用 N_() 标记的字符串需要在代码中引用时传递给 gettext 翻译例程。例如,请查看 subversion/svn/help-cmd.c 中如何处理页眉和页脚。Q_() 用于具有单数和复数形式的消息。
除了 _()、N_() 和 Q_() 宏之外,还使用 U_() 来标记不会被翻译的字符串,因为通常翻译内部错误消息没有用。这应该只影响大多数用户永远不会看到的模糊错误消息(由 Subversion 中的错误或非常特殊的存储库损坏引起)。使用 U_() 的原因是明确指出 gettext 调用并非遗漏。
当使用对 gettext 例程(*gettext 或 *dgettext)的直接调用时,请记住 Subversion 代码的大部分是库代码。因此,默认域不一定是 Subversion 自己的域。在库代码中,您应该使用 gettext 函数的 dgettext 版本。域名称在 PACKAGE_NAME 定义中定义。
本地化所需的所有设置由 svn_private_config.h(对于 *nix)和 svn_private_config.hw(对于 Windows)中的 ENABLE_NLS 条件控制。请确保将
#include "svn_private_config.h"
作为任何需要本地化的文件的最后一个包含。
还要注意,_()、Q_() 和 *gettext() 调用的返回值是 UTF-8 编码的;这意味着它们应该被翻译成当前的区域设置,并以任何形式的程序输出写入。
GNU gettext 手册 (https://gnu.ac.cn/software/gettext/manual/html_node/gettext_toc.html) 在其“准备程序源代码”部分提供了有关编写可翻译程序的更多信息。它的提示主要适用于字符串组合。
目前可用的翻译可以在仓库的 po 部分找到。如果您想开始一个尚未提供的翻译,请联系 dev@subversion.apache.org。翻译讨论将在该列表中进行。
Makefile 构建目标 locale-gnu-*(用于维护 po 文件)需要 GNU gettext 0.13 或更高版本。请注意,对于那些想要将 *.po 文件编译成 *.mo 的人来说,这不是必需的。
在开始新的翻译之前,请与 Subversion 开发邮件列表联系,以确保您没有重复工作。另外请注意,该项目强烈偏好由多人维护的翻译:在邮件列表中发布您的意图可能有助于您找到支持者。
之后,您应该执行以下步骤
./autogen.sh./configuremake locale-gnu-potsubversion/po 目录中运行 msginit --locale LOCALE -o LOCALE.po。LOCALE 是用于标识您的区域设置的 ll[_LL] 语言和国家代码。步骤 (2) 和 (3) 生成一个 Makefile;步骤 (4) 生成 subversion/po/subversion.pot
Subversion 项目有一个策略,即不在其文件中添加姓名,因此请应用以下两个更改。
新生成的 .po 文件中的标题如下所示
# SOME DESCRIPTIVE TITLE. # Copyright (C) YEAR THE PACKAGE'S COPYRIGHT HOLDER # This file is distributed under the same license as the PACKAGE package. # FIRST AUTHOR <EMAIL@ADDRESS>, YEAR.
请将该块替换为以下文本
# <Your language> translation for subversion package # Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # https://apache.ac.cn/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, # software distributed under the License is distributed on an # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY # KIND, either express or implied. See the License for the # specific language governing permissions and limitations # under the License.
.po 文件中的第一个翻译块包含两行,如下所示
"Last-Translator: FULL NAME <EMAIL@ADDRESS>\n" "Language-Team: LANGUAGE <LL@li.org>\n"
请将它们替换为以下两行
"Last-Translator: Subversion Developers <dev@subversion.apache.org>\n" "Language-Team: YOUR LANGUAGE <dev@subversion.apache.org>\n"
待记录
在提交到邮件列表或提交到仓库之前,请确保您的 po 文件“编译”。您可以通过以下步骤(在基于 Makefile 的系统上)执行此操作
./autogen.sh./configure(使用适当的参数)make localeautogen.sh 步骤很重要,因为它将新的 po 文件添加为 'locale' 构建目标的依赖项。但是请注意,步骤 1 和 2 只需要在您添加新翻译后执行一次。
请不要将大型 po 文件发送到邮件列表。dev@subversion.apache.org 上有许多订阅者使用的是慢速连接,他们不希望通过电子邮件收到大型文件。相反,请将 po 文件放置在互联网上的某个位置供下载,并仅发布 URL。如果您没有可用的网站,请在 dev@ 上询问,有人会帮助您找到一个位置。
当然,如果您对 Subversion 存储库有提交权限,您可以直接将 po 文件提交到那里,假设所有其他要求都已满足。
构建系统的基于 Makefile 的部分包含一个 make 目标,以方便维护现有的 po 文件。要在具有 GNU gettext 的系统上更新 po 文件,请运行
make locale-gnu-po-update
要仅更新特定语言,您可以使用
make locale-gnu-po-update PO=ll
其中 ll 是 po 文件的名称,不带扩展名(即 PO=sv)。
建议使用两个提交来完成 .po 更新;一个在“make locale-gnu-po-update”之后,另一个在翻译完成后。这有两个优点
gettext(1) 会产生大量的行号更改,这使得生成的 diff 难以被其他翻译人员审查。通过两次提交,所有行号更改都存储在第一次提交中,第二次提交包含所有实际翻译,没有额外的垃圾。在 trunk 中编辑 po 文件非常简单,但当这些更改要转移到发布分支时会变得更加复杂。项目策略是不在发布分支上进行任何直接更改,提交到分支的所有内容都应该从 trunk 合并。这也适用于 po 文件。使用 svn merge 来完成工作会导致冲突和模糊消息,因为 gettext 会更改行号和字符串格式。
svn merge 进行分支更新时存在的任何复杂性。以下规则适用
执行 `make locale-gnu-po-update` 命令。以上列出了分支上 po 文件允许的所有操作。
可以使用以下命令将 trunk 版本 X 的 YY.po 文件合并到您的分支工作副本中。
svn cat -r X ^/subversion/trunk/subversion/po/YY.po | \
po-merge.py YY.po
在某些 gettext 实现中,我们需要确保 mo 文件(无论是通过项目获得还是本地创建)都使用 UTF-8 编码。这个要求源于 Subversion 在内部使用 UTF-8,一些实现会翻译成活动语言环境,以及 `bind_textdomain_codeset()` 在不同实现之间不可移植的事实。
为了满足这个要求,po 文件必须使用 UTF-8 编码。如果目标系统上的 gettext 实现不支持 `bind_textdomain_codeset()`,构建系统将确保 mo 文件使用 UTF-8 编码,方法是从 po 文件头中删除 Content-Type 头。请注意,一些 msgfmt 工具不喜欢缺少字符集指示符,并且会生成类似于“无法进行字符集转换”的警告。您可以安全地忽略这些警告。一些 gettext 实现使用 msgid 为 ""(空字符串)的部分来保存管理数据。其中一个建议的标题是 'Last-Translator:' 字段。由于 Subversion 项目的政策是不在特定文件中命名贡献者,而是在仓库日志消息中给予认可,因此您需要不要在该字段中填写您的姓名。
由于某些工具需要该字段才能将 po 文件视为有效(例如 Emacs PO 模式),您可以在该字段中填写 "dev@subversion.apache.org"。
该项目已将引号的使用标准化。一些翻译团队也做到了这一点。如果您的语言环境没有翻译团队,或者他们没有标准化引号的使用,请遵循本指南其他地方的项目指南。如果他们已经标准化了:请遵循他们的标准 :-)